
|


 КореяЯн Лангнер ГмбХ
КореяЯн Лангнер ГмбХ
 jpg”>
jpg”>
 (шт.)
(шт.) (28шт.)
(28шт.)
 (шт.)
(шт.)
 jpg” bgcolor=”#85c0fe”>
jpg” bgcolor=”#85c0fe”>Основные модели образования – Организация учебного процесса
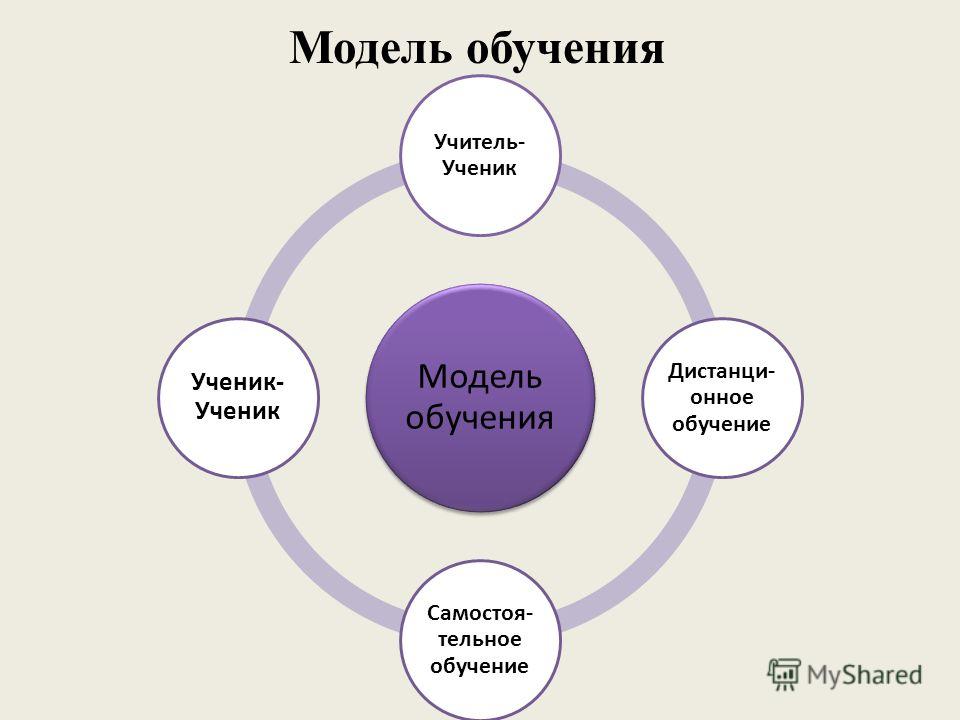
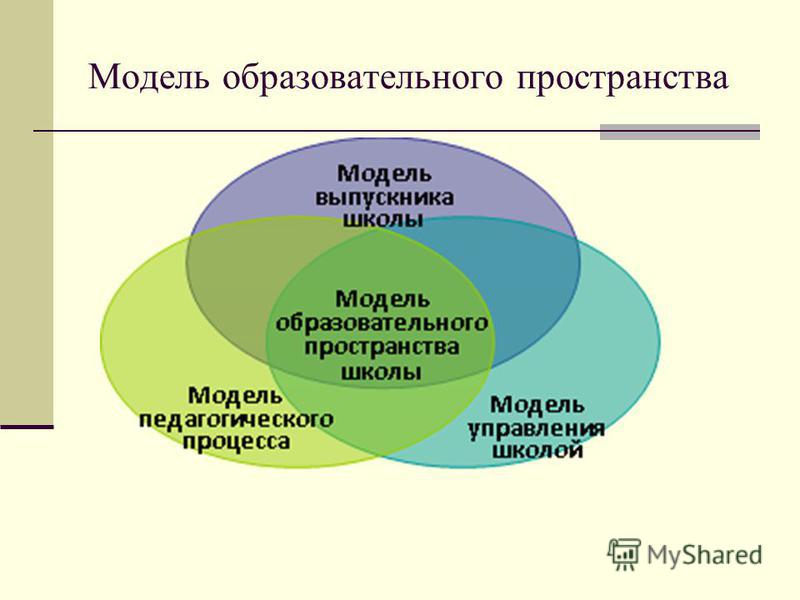
Основные модели образования
|
Робот подобрал для Вас материалы, похожие на этот. Посмотреть По материалам моих лекций В педагогической литературе часто встречаются термины модель образования (образовательная модель) и модель обучения. Под моделью образования, как правило, понимается модель, отражающая те или иные представления об организации образовательного процесса в целом, включая не только обучение, но и воспитание, развитие личности. Характеризуя модель образования, некоторые авторы рассматривают её как реализацию определённого научного подхода, как особый способ организации образовательного пространства, взаимодействия различных образовательных организаций и построения системы образования. Модель образования – это мысленно представленная система, отражающая тот или иной подход к образованию, взгляд на его роль в жизни человека и общества. Есть несколько подходов к выделению моделей образования. Так, М. В. Кларин считает, что все образовательные модели можно разделить на традиционные («знаниевые», целью которых является формирование у учащихся знаний, умений и навыков) и инновационные (развивающие, направленные на развитие личности ученика). В ряде научных публикаций модели образования подразделяются на технократические и гуманистические. Главными педагогическими ценностями в технократических моделях являются знаний, умения и навыки (ЗУНы). Основные педагогические ценности гуманистических образовательных моделей – личность ребёнка, её гармоничное развитие (И.П. Подласый). Н. В. Бордовская и А. А. Реан выделяют следующие модели образования. Модель образования как государственно-ведомственной организации. В этой модели образование выступает одной из отраслей народного хозяйства и строится по ведомственному принципу с жёстким централизованным определением целей и содержания образования, типов образовательных организаций и состава учебных дисциплин для каждого типа. Модель развивающего образования (В. В. Давыдов, В. В. Рубцов и др.) отличается кооперацией образовательных организаций разного типа и уровня. Это расширяет спектр образовательных услуг и максимально удовлетворяет потребности в образовании у различных слоёв населения. Кроме того обеспечивается способность быстро реагировать на постоянно происходящие в обществе изменения спроса на те или иные профессии и специальности. Однако и у этой модели есть недостатки. Так, её реализация невозможна без соответствующей инфраструктуры, без развитой сети образовательных организаций разного типа и профиля. Применительно к России с её большими и неравномерно населёнными территориями очень сложно создать такую инфраструктуру, которая обеспечивала бы всем жителям страны равные возможности в получении образования, ориентированного на максимальное развитие личности. Модель систематического академического образования (Ж. Мажо, Л. Кро, Д. Равич и др.) считается традиционным способом передачи новому поколению культурного опыта прошлого. Данная модель нацелена на формирование системы базовых знаний и умений, позволяющих индивиду в дальнейшем перейти к самостоятельному усвоению знаний, ценностей, опыта. Для традиционной модели характерно многообразие усваиваемогго материала; это обусловлено тем, что традиционном образовании заранее неизвестно, что именно понадобится каждому человеку в дальнейшем, обширная программа даёт личности ученика более широкие возможности для дальнейшего самоопределения. Таким образом, главное достоинство традиционной модели – научная основа формируемых знаний и опыта и систематический характер полученного индивидом образования. Недостаток: ориентированность в большей степени на некий идеальный уровень образованности, а не реальные жизненные потребности. Рационалистическая модель (П. Блум, Р. Ганье и др. Феноменологическая модель (А. Маслоу, А. Комбс, К. Роджерс и др.) основана на персональном обучении, учитывающем индивидуальные психологические особенности учащегося, на уважительном отношении к его интересам и потребностям. Приверженцы феноменологической модели отвергают взгляд на школу как на «образовательный конвейер» (само название модели – производное от слова «феномен» – свидетельствует о том, что каждый ученик уникален). Неинституциональная модель (П. Гудман, И. Иллич, Ф. Клейн и др.) – это образование вне школ, вузов и других социальных институтов: дистанционное обучение, обучение через книги, средства массовой информации, мультимедийные учебники, сеть Интернет и т.п. Очевидный плюс данной модели – максимальная свобода выбора обучающимся места, времени, профиля и способа обучения, возможность обучаться вне зависимости от места проживания. Однако свобода является плюсом при условии, что человек готов самостоятельно организовать свою учебную деятельность, а это возможно только, когда он уже имеет солидный опыт учения и сильную мотивацию самообразования. Кроме того, непривязанность обучения к какому-либо социальному институту лишает неинституциальное образования официального статуса и не позволяет обучающемуся получить документ об образовании государственного образца. Таким образом, любая из существующих сегодня моделей образования имеет как достоинства, так и недостатки. Поэтому в развитых системах образования можно встретить различные модели, в том числе – новые, возникающие на основе вышеописанных. Например, среди тенденций последнего десятилетия – включение университетов в развитие дистанционного образования в сети Интернет. Университетское образование относится к традиционной модели, а дистанционное – к неинституциональной. Их слияние позволяет преодолевать недостатки, присущие каждой из этих моделей в отдельности (например, обучаясь дистанционно, получить диплом о высшем образовании или освоить практикоориентированный курс на университетской образовательной онлайн-платформе). Робот обнаружил, что со статьёй “Основные модели образования” тематически связаны: Для ссылки: Сидоров С.В. Основные модели образования [Электронный ресурс] // Сидоров С.  В. Сайт педагога-исследователя – URL: http://si-sv.com/publ/osnovnye_modeli_obrazovanija/14-1-0-504 (дата обращения: 20.09.2022). В. Сайт педагога-исследователя – URL: http://si-sv.com/publ/osnovnye_modeli_obrazovanija/14-1-0-504 (дата обращения: 20.09.2022).
| |
| Автор(ы): Сидоров С.В. | Опубликовано 23.09.2015 | Просмотров: 97199 | |
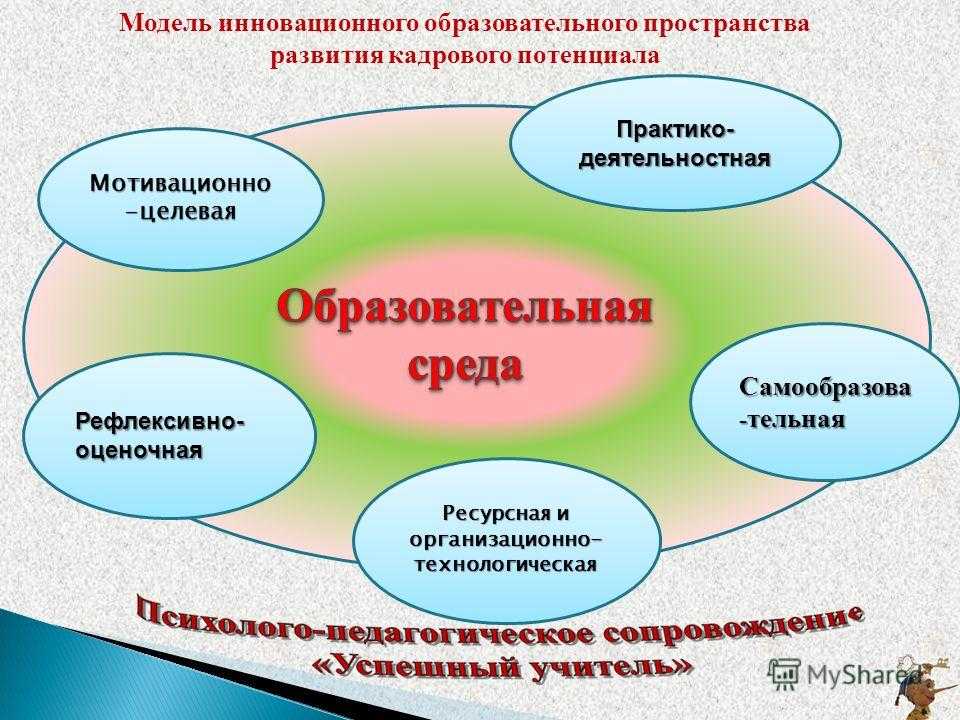
 Традиционные основываются на субъект-объектном взаимодействии педагога с обучающимися и воспроизведении образцов знаний, деятельности, правил и алгоритмов. Основа инновационных моделей – субъект-субъектные, сотрудничающие взаимоотношения между учителем и учеником. В инновационных моделях образовательный процесс строится как решение проблем и подразумевает высокую самостоятельность учащихся.
Традиционные основываются на субъект-объектном взаимодействии педагога с обучающимися и воспроизведении образцов знаний, деятельности, правил и алгоритмов. Основа инновационных моделей – субъект-субъектные, сотрудничающие взаимоотношения между учителем и учеником. В инновационных моделях образовательный процесс строится как решение проблем и подразумевает высокую самостоятельность учащихся.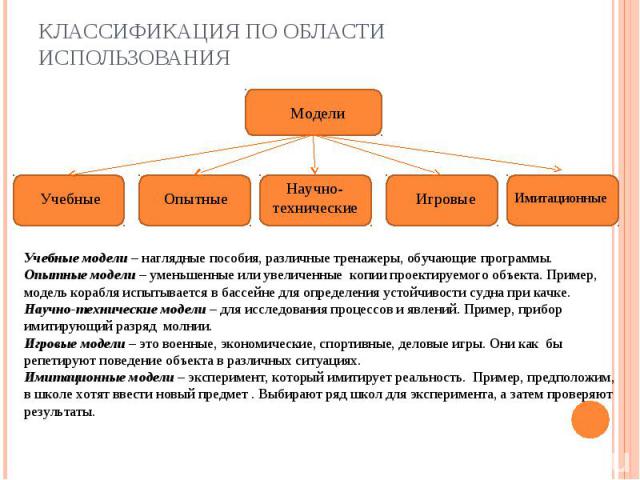 Главное достоинство: возможность централизованного распределения средств (финансирования образовательных организаций, прогнозирования потребности специалистов исходя из тенденций развития той или иной отрасли и т.д.). Главный недостаток: мало возможностей для индивидуализации образования, для учёта потребностей личности каждого ученика, студента.
Главное достоинство: возможность централизованного распределения средств (финансирования образовательных организаций, прогнозирования потребности специалистов исходя из тенденций развития той или иной отрасли и т.д.). Главный недостаток: мало возможностей для индивидуализации образования, для учёта потребностей личности каждого ученика, студента.
 ) предполагает такую организацию образования, которая обеспечивает, прежде всего, практическое приспособление молодого поколения к обществу, к существующим социальным условиям. Знания и опыт, полученные при такой модели образования, позволяют личности безболезненно войти в систему общественных отношений, занять в ней свою социальную нишу. Это её главное достоинство. В качестве главного недостатка можно назвать чрезмерную специализированность получаемого образования, пренебрежение широкими научными знаниями, что в дальнейшем существенно ограничивает выпускника в выборе профессии, а при необходимости изменить сферу заработка создаёт трудности в профессиональной переподготовке.
) предполагает такую организацию образования, которая обеспечивает, прежде всего, практическое приспособление молодого поколения к обществу, к существующим социальным условиям. Знания и опыт, полученные при такой модели образования, позволяют личности безболезненно войти в систему общественных отношений, занять в ней свою социальную нишу. Это её главное достоинство. В качестве главного недостатка можно назвать чрезмерную специализированность получаемого образования, пренебрежение широкими научными знаниями, что в дальнейшем существенно ограничивает выпускника в выборе профессии, а при необходимости изменить сферу заработка создаёт трудности в профессиональной переподготовке. Личностная направленность образования – безусловное достоинство феноменологической модели. К её недостаткам можно отнести сравнительно высокие затраты на индивидуальное образование, возрастающие требования к профессиональной квалификации педагогов. Поэтому сегодня в мира нет опыта абсолютной реализации данной модели в массовой школе.
Личностная направленность образования – безусловное достоинство феноменологической модели. К её недостаткам можно отнести сравнительно высокие затраты на индивидуальное образование, возрастающие требования к профессиональной квалификации педагогов. Поэтому сегодня в мира нет опыта абсолютной реализации данной модели в массовой школе. Поэтому данная модель рассматривается как способ дополнительного образования и саморазвития.
Поэтому данная модель рассматривается как способ дополнительного образования и саморазвития.31. Учебные компьютерные модели
Непрерывное и быстрое расширение областей исследования, в которых удается эффективно использовать математические методы, составляет одну из характерных черт развития современной науки. Раздвигая традиционные рамки «точных наук», этот процесс вовлекает сегодня в свою сферу биологию и социологию, языкознание и психологию, юриспруденцию и историю. Применение математических методов открывает во всех этих областях знаний пути для более глубокого проникновения в сущность и закономерности изучаемых явлений, более точного предсказания их развития в различных условиях, а значит, и более эффективного управления ими, практического их использования
Модель Колмогорова, связанная с педагогикой
Несмотря
на потребность
в применении математических методов в
педагогике, специалисты
в области
математики
отмечают,
что применение математических методов
в социальных и
гуманитарных
науках
связано с большими трудностями, так
как
выделение однородного
качества и его математическое изучение
затруднены тем, что
при этом
приходится учитывать и такие субъективные
факторы,
как
воля, цели, ценностные
ориентировки
и
мотивации
людей. Основная трудность
в этом
случае состоит
в построении
качественной
теории
процессов. Если не учитывать
этого,
возникает
опасность бесплодного увлечения
формулами и
математическим
аппаратом,
за которыми исследователи перестают
видеть
реальное
содержание изучаемых процессов.
Фактически
речь
идет об опасности узкого подхода к
сложнейшим, многофакторным
явлениям
социального, а следовательно, и
педагогического порядка. На
необходимость
применять
методы
точных
наук с учетом специфики объектов такого
применения
указывают многие крупные учёные.
Основная трудность
в этом
случае состоит
в построении
качественной
теории
процессов. Если не учитывать
этого,
возникает
опасность бесплодного увлечения
формулами и
математическим
аппаратом,
за которыми исследователи перестают
видеть
реальное
содержание изучаемых процессов.
Фактически
речь
идет об опасности узкого подхода к
сложнейшим, многофакторным
явлениям
социального, а следовательно, и
педагогического порядка. На
необходимость
применять
методы
точных
наук с учетом специфики объектов такого
применения
указывают многие крупные учёные.
Таким образом, можно утверждать, что применение математических методов в педагогикеограничено спецификой гуманитарной сферы. Тем не менее Л. Н. Колмогоров не отрицает возможности применения математических методов в науках, изначально достаточно далеких от математики, в том числе и гуманитарных.
Одним
из
важных математических методов являетсяматематическое моделирование.
Математические модели представляют
собой многофункциональноедидактическое
средство,
способствующее решению разнообразных
педагогических
задач. Возможности
этого средства остаются до сих пор
недостаточно раскрытыми.
Несмотря
на то, что такие модели являются формальным
инструментарием
познания, его
использование способствует достижению
не толькообразовательных,
но и развивающих
дидактических целей. Эго объясняетсятем,
что модели, неразрывно связанные
с конкретным содержанием учебного
предмета,помогаютего
представить
ярко, выпукло, соединив строгость научныхрассуждений
с глубоким научным анализом
структур изучаемых процессов и явленийлюбой
качественной природы.
Рассмотрим пример применения математических
моделейк
процессу обучения
в группе.
Возможности
этого средства остаются до сих пор
недостаточно раскрытыми.
Несмотря
на то, что такие модели являются формальным
инструментарием
познания, его
использование способствует достижению
не толькообразовательных,
но и развивающих
дидактических целей. Эго объясняетсятем,
что модели, неразрывно связанные
с конкретным содержанием учебного
предмета,помогаютего
представить
ярко, выпукло, соединив строгость научныхрассуждений
с глубоким научным анализом
структур изучаемых процессов и явленийлюбой
качественной природы.
Рассмотрим пример применения математических
моделейк
процессу обучения
в группе.
Математическое образование в учебных заведениях связано, преждевсего, с обучением в группе. Необходимой предпосылкой эффективности групповогообучения является адекватный подбор последовательности (траектории) изученияэлементов знания из учебного пособия в соответствии с поставленными целями.
Обучение
в группе
допускает различные стратегии.
Одна изних,
например, предполагает изучение
всех элементов знания за исключением
знанийусвоенных
каждым учеником группы. При такой стратегии практически каждомуученику
преходится затрачивать время
на повторное изучение уже известных
емуэлементов
знания.Другая
стратегия
группового обучения предполагает
изучениенового
материала,ориентируясь
на
«средний» уровень знаний учащихся
группы. Вторая стратегияобучения
в большей
степени учитывает начальную подготовку
учащихся, во требуетразработки
ни
диви дуальных траекторий выравнивания
знаний каждого из учеников.
При такой стратегии практически каждомуученику
преходится затрачивать время
на повторное изучение уже известных
емуэлементов
знания.Другая
стратегия
группового обучения предполагает
изучениенового
материала,ориентируясь
на
«средний» уровень знаний учащихся
группы. Вторая стратегияобучения
в большей
степени учитывает начальную подготовку
учащихся, во требуетразработки
ни
диви дуальных траекторий выравнивания
знаний каждого из учеников.
ПримерПустьGUI,OU2,…,GUk- графы, представляющие модели знанийучеников Ul,U2,…,Uk; ОС -модель цели обучения;NZ- набор задач. Опишемалгоритм построения ориентированной на первую стратегию обучения моделизнаний труппыUgучащихся:
окрасить вершины и дуги графаQ=GCв черный цвет;
все вершины и ребра графаG, входящие в модель знаний каждого ученика Ug, окрасить в зеленыйцвет.
Полученный таким образом цветной граф
называется моделью знаний группы Ug,
учащихся,
ассоциированнойс
цельюобучения
GC.
Второй алгоритм построения модели знаний группы ориентирован на вторую стратегию обучения. При такой стратегии материал, усвоенный большей частью группы, изучается только учащимися плохо знакомыми с данным материалом:
окрасить вершины и дуги графа G=GCв черный цвет;
все вершины и ребра графа G, входящие в половину и более моделей знаний учениковGUi(i= 1,.., к), окрасить в синий цвет;
все вершины и ребра графа G, входящие в каждую из моделей знаний учениковGUi, гдеi=I,к,окрасить в зеленый цвет.
Получим цветной граф GUg, который называется ассоциированной с целью обученияGCмоделью знаний группыUg учащихся и обозначаетсяM3r(Ug).
Ликвидация пробелов в знаниях учащихся производится по индивидуальной траектории выравнивания для каждого из учащихся.
Программные средства для моделирования предметно-коммуникативных сред (предметной области)
В настоящее время имеется большой набор
компьютерных проектных сред, предназначенных
для использования в учебном процессе. Одним из таких примеров IpSMRCflпакет «Живая геометрия». Он предназначен
для построения и изучения основных
геометрических объектов и их характеристик.
Это электронный аналог готовальни,
позволяющий создавать интерактивные
чертежи, а также выполнять различные
измерения. Программа позволяет
организовать деятельность учащихся по
построению моделей геометрических
объектов и исследованию их свойств.
Подобные пакеты могут использоваться
на уроках: либо учениками – в качестве
средства решения задач, либо учителем
— в качестве средства предоставления
учебной задачи путем оформления
определенного сценария, позволяющего
организовать демонстрацию задачи и ее
решения, вызов справочной информации
и т. п.
Одним из таких примеров IpSMRCflпакет «Живая геометрия». Он предназначен
для построения и изучения основных
геометрических объектов и их характеристик.
Это электронный аналог готовальни,
позволяющий создавать интерактивные
чертежи, а также выполнять различные
измерения. Программа позволяет
организовать деятельность учащихся по
построению моделей геометрических
объектов и исследованию их свойств.
Подобные пакеты могут использоваться
на уроках: либо учениками – в качестве
средства решения задач, либо учителем
— в качестве средства предоставления
учебной задачи путем оформления
определенного сценария, позволяющего
организовать демонстрацию задачи и ее
решения, вызов справочной информации
и т. п.
Пакет
«Живая физика»
— это компьютерная проектная среда, с
помощьюкоторой
можно
организовать
деятельность по моделированию объектов,
процессов иявлений.
Набор
объектов,
законы, формулы и т. п. уже заданы.
Пользовательвыбирает
ит
предоставляемого
набора какой-либо объект, устанавливает
егопараметры,
святи
с другимиобъектами
и внешние
условия проведения эксперимента. Естьвозможность
использования
виртуальных измерительных инструментов
ивыбора
способа
представления
результатов: мультипликация, график,
таблица,вектор.
.пакет может
быть востребован при изучении школьного
курсафизики
или в старших
классах науроках
математики
или информатики прирассмотрении
тем, связанных
с компьютерным
моделированием. Он призван помочьучащимся
понять теорию, научиться
решать задачи,
самостоятельно организоватьи
провести эксперименты.
Естьвозможность
использования
виртуальных измерительных инструментов
ивыбора
способа
представления
результатов: мультипликация, график,
таблица,вектор.
.пакет может
быть востребован при изучении школьного
курсафизики
или в старших
классах науроках
математики
или информатики прирассмотрении
тем, связанных
с компьютерным
моделированием. Он призван помочьучащимся
понять теорию, научиться
решать задачи,
самостоятельно организоватьи
провести эксперименты.
Специфика использования компьютерного моделировании в педагогических программных средствах
Важную часть информационной среды школы составляет правильно подобранный набор программного обеспечения, в состав ко торого могу т входить:
– программные средства общего назначения для работы со всеми видами информации;
I источники информации в форме электронных энциклопедий и коллекций текстов, изображений, видео и т. д.;
виртуальные лаборатории/конструкторы, позволяющие создавать наглядные н символические имитационные модели математической, физической и биологической реальности и проводить эксперименты о этими моделями;
■ интегрированные
творческие среды, включающие в себя
редакторы тек- рщрфики, музыки и набор
программируемых объектов.
Важнейшая задача современной школы – гармоническое развитие личности, которое основывается на прочных знаниях, овладении определенными навыками и умение применять их на практике.Мастерство учителя основано на умении строить процесс обучения в соответствии сзакономерностями этою процесса, одним из которых является принцип наглядности.Использование наглядности в обучении имеет как сторонников, так и противников. Это свидетельствует о нечетком понимании принципа наглядности, дополненногонедавно принципом моделирования. Вторым фактором, определяющим качествообучения, являютсяспособности учащихся. Чтобы расширить сферу чувственного познания и как-то воспринимать объекты, непосредственно чувственно не воспринимаемые, разрабатываются особые методы и средства. Эго разного рода приборы, усиливающие органы чувств (на* пример – телескоп X приборы для восприятия объектов прошлого (фотоаппарат) шт объекты, находящиеся в замкнутом пространстве и далеко (телевидение).
Если говорить о программных средствах
для построения компьютерных моделей,
то все авторы рекомендуют использовать
наиболее популярное средство компьютерного
моделирования – электронные таблицы. СУБД не задумывалось как средство
моделирования, но создание информационных
моделей объектов с возможностью проводить
при помощи таких моделей выборку
информации, удовлетворяющей каким-либо
условиям с целью дальнейшего анализа
этого объекта, позволяет проводить
моделирование с помощью баз данных,
СУБД не задумывалось как средство
моделирования, но создание информационных
моделей объектов с возможностью проводить
при помощи таких моделей выборку
информации, удовлетворяющей каким-либо
условиям с целью дальнейшего анализа
этого объекта, позволяет проводить
моделирование с помощью баз данных,
Алгоритмические языки
программировании
издавна используются для построения
моделей. Если
нет
возможности
использовать для построения моделей
другие средства, то спомощью
языков
программирования можно строить модели
из самых различных классовмоделей
(физические
и логические, геометрические и
экологические и т. п.). У А. Г. Кушнеренко
приводится пример построения модели
зрительного зала. Здеськомпьютерная
модель
зрительного зала – это программа
на
учебном
алгоритмическомязыке,
которая
затем должна быть реализована на языке
программирования. Для тогочтобы
ученик
в 9-м классе построил такую модель (в
ней множество встроенныхциклов)
необходимо,
чтобы он достаточно хорошоумел
программировать. Но,к
сожалению,
процент
девятиклассников, которые слегкостью
используют
встроенныециклы,
совсем
невелик.
Но,к
сожалению,
процент
девятиклассников, которые слегкостью
используют
встроенныециклы,
совсем
невелик.
Математические модели демографии – учебный курс
- Автор: Лебедев А.В.
- Год создания: 2003
- Организация: МГУ имени М.В. Ломоносова
- Описание: Курс (полугодовой) обязательный для студентов 5 курса экономического потока. Излагаются математические модели демографии, как классические, так и современные. Автором выпущены учебные пособия по курсу, последнее в 2017 году (см. https://istina.msu.ru/publications/book/51434817/ ) Программа курса регулярно обновляется, последнее обновление – в 2019 году. С весны 2020 года читается также магистрам 1-го года МШЭ МГУ по программе “Экономика и математические методы”.
- Добавил в систему: Лебедев Алексей Викторович
Прикрепленные файлы
| № | Имя | Описание | Имя файла | Размер | Добавлен |
|---|---|---|---|---|---|
1. |
Руководства по темам курса (для дистанционного обучения) | MD-2020.ZIP | 5,5 МБ | 24 августа 2020 [aleb] | |
| 2. | Теория ветвящихся случайных процессов (Т.Харрис) | Harris_T.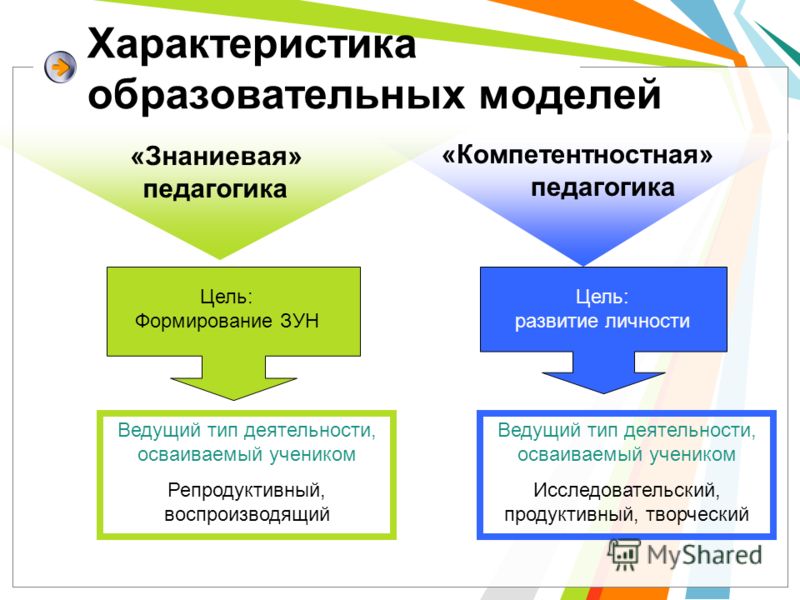 _Sevastyanov_B.A.per._SHteinpress_L.BookFi.djvu _Sevastyanov_B.A.per._SHteinpress_L.BookFi.djvu |
5,1 МБ | 18 марта 2020 [aleb] | |
| 3. | Работы И.А.Алешковского | aleshkovski.zip | 871,1 КБ | 1 января 2021 [aleb] | |
4. |
Сборник задач по математической демографии (А.В.Лебедев, 2017, с исправлениями 2022) | tekst_Lebedev_itog22.pdf | 2,5 МБ | 11 июля 2022 [aleb] | |
| 5. | Статья в “Техника-молодежи” (А.В.Лебедев, 2001) | DEMO. pdf pdf |
123,2 КБ | 15 февраля 2022 [aleb] | |
| 6. | Профстандарт Демограф | Prikaz_Ob_utverzhdenii_professionalnogo_standarta_Demogra… | 1,1 МБ | 11 июля 2022 [aleb] | |
7. |
Краткая история математической динамики населения (Н.Бакаэр) | ru.pdf | 1,2 МБ | 6 августа 2021 [aleb] | |
| 8. | Рабочая программа курса (2019) | RP-MMD-2019.pdf | 172,3 КБ | 13 августа 2019 [aleb] | |
9. |
Азы математической демографии (Староверов О.В.) | Staroverov_O.V._Azue_matematicheskoi_demografiiBookFi.org… | 2,4 МБ | 31 августа 2019 [aleb] | |
| 10. | Изучение продолжительности жизни (сборник) | demogr08. pdf pdf |
10,7 МБ | 31 августа 2019 [aleb] | |
| 11. | Интересные ссылки по демографии | Demografiya-ssyilki-2019.pdf | 69,6 КБ | 31 августа 2019 [aleb] |
Преподавание курса
- 7 февраля 2022 – 31 мая 2022 Лебедев Алексей Викторович
-
МГУ имени М.
 В. Ломоносова, Московская школа экономики
В. Ломоносова, Московская школа экономики
- обязательная, вариативной части, лекции, 28 часов
- Автор: Лебедев А.В.
- 1 сентября 2021 – 31 декабря 2021 Лебедев Алексей Викторович
- МГУ имени М.В. Ломоносова, Механико-математический факультет, Отделение математики, Кафедра теории вероятностей
- обязательная, вариативной части, лекции, 36 часов
- Автор: Лебедев А.В.
- 1 сентября 2021 – 31 декабря 2021 Лебедев Алексей Викторович
-
МГУ имени М.
 В. Ломоносова, Механико-математический факультет, Отделение математики, Кафедра теории вероятностей
В. Ломоносова, Механико-математический факультет, Отделение математики, Кафедра теории вероятностей
- обязательная, вариативной части, семинары, 36 часов
- Автор: Лебедев А.В.
- 8 февраля 2021 – 31 мая 2021 Лебедев Алексей Викторович
- МГУ имени М.В. Ломоносова, Московская школа экономики
- обязательная, вариативной части, лекции, 28 часов
- Автор: Лебедев А.В.
- 1 сентября 2020 – 31 декабря 2020 Лебедев Алексей Викторович
-
МГУ имени М.
 В. Ломоносова, Механико-математический факультет, Отделение математики, Кафедра теории вероятностей
В. Ломоносова, Механико-математический факультет, Отделение математики, Кафедра теории вероятностей
- обязательная, вариативной части, семинары, 36 часов
- Автор: Лебедев А.В.
- 1 сентября 2020 – 31 декабря 2020 Лебедев Алексей Викторович
- МГУ имени М.В. Ломоносова, Механико-математический факультет, Отделение математики, Кафедра теории вероятностей
- обязательная, вариативной части, лекции, 36 часов
- Автор: Лебедев А.В.
- 7 февраля 2020 – 31 мая 2020 Лебедев Алексей Викторович
-
МГУ имени М.
 В. Ломоносова, Московская школа экономики
В. Ломоносова, Московская школа экономики
- обязательная, вариативной части, лекции, 28 часов
- Автор: Лебедев А.В.
- 2 сентября 2019 – 31 декабря 2019 Лебедев Алексей Викторович
- МГУ имени М.В. Ломоносова, Механико-математический факультет, Отделение математики, Кафедра теории вероятностей
- обязательная, вариативной части, лекции, 36 часов
- Автор: Лебедев А.В.
- 2 сентября 2019 – 31 декабря 2019 Лебедев Алексей Викторович
-
МГУ имени М.
 В. Ломоносова, Механико-математический факультет, Отделение математики, Кафедра теории вероятностей
В. Ломоносова, Механико-математический факультет, Отделение математики, Кафедра теории вероятностей
- обязательная, вариативной части, семинары, 36 часов
- Автор: Лебедев А.В.
- 1 сентября 2018 – 31 декабря 2018 Лебедев Алексей Викторович
- МГУ имени М.В. Ломоносова, Механико-математический факультет, Отделение математики, Кафедра теории вероятностей
- обязательная, вариативной части, семинары, 36 часов
- Автор: Лебедев А.В.
- 1 сентября 2018 – 31 декабря 2018 Лебедев Алексей Викторович
-
МГУ имени М.
 В. Ломоносова, Механико-математический факультет, Отделение математики, Кафедра теории вероятностей
В. Ломоносова, Механико-математический факультет, Отделение математики, Кафедра теории вероятностей
- обязательная, вариативной части, лекции, 36 часов
- Автор: Лебедев А.В.
- 1 сентября 2017 – 31 декабря 2017 Лебедев Алексей Викторович
- МГУ имени М.В. Ломоносова, Механико-математический факультет, Отделение математики, Кафедра теории вероятностей
- обязательная, вариативной части, лекции, 36 часов
- Автор: Лебедев А.В.
- 1 сентября 2017 – 31 декабря 2017 Лебедев Алексей Викторович
-
МГУ имени М.
 В. Ломоносова, Механико-математический факультет, Отделение математики, Кафедра теории вероятностей
В. Ломоносова, Механико-математический факультет, Отделение математики, Кафедра теории вероятностей
- обязательная, вариативной части, семинары, 36 часов
- Автор: Лебедев А.В.
- 1 сентября 2016 – 30 декабря 2016 Лебедев Алексей Викторович
- МГУ имени М.В. Ломоносова, Механико-математический факультет, Отделение математики, Кафедра теории вероятностей
- обязательная, вариативной части, лекции, 36 часов
- Автор: Лебедев А.В.
- 1 сентября 2016 – 30 декабря 2016 Лебедев Алексей Викторович
-
МГУ имени М.
 В. Ломоносова, Механико-математический факультет, Отделение математики, Кафедра теории вероятностей
В. Ломоносова, Механико-математический факультет, Отделение математики, Кафедра теории вероятностей
- обязательная, вариативной части, семинары, 36 часов
- Автор: Лебедев А.В.
- 1 сентября 2015 – 30 декабря 2015 Лебедев Алексей Викторович
- МГУ имени М.В. Ломоносова, Механико-математический факультет, Отделение математики, Кафедра теории вероятностей
- обязательная, вариативной части, лекции, 36 часов
- Автор: Лебедев А.В.
- 1 сентября 2015 – 30 декабря 2015 Лебедев Алексей Викторович
-
МГУ имени М.
 В. Ломоносова, Механико-математический факультет, Отделение математики, Кафедра теории вероятностей
В. Ломоносова, Механико-математический факультет, Отделение математики, Кафедра теории вероятностей
- обязательная, вариативной части, семинары, 18 часов
- Автор: Лебедев А.В.
- 1 сентября 2014 – 31 декабря 2014 Голдаева Анна Алексеевна
- МГУ имени М.В. Ломоносова, Механико-математический факультет
- обязательная, базовой части, лекции, 36 часов
- Автор: Лебедев А.В.
- 1 сентября 2014 – 31 декабря 2014 Голдаева Анна Алексеевна
-
МГУ имени М.
 В. Ломоносова, Механико-математический факультет
В. Ломоносова, Механико-математический факультет
- обязательная, базовой части, семинары, 18 часов
- Автор: Лебедев А.В.
- 1 сентября 2013 – 31 декабря 2013 Лебедев Алексей Викторович
- МГУ имени М.В. Ломоносова, Механико-математический факультет, Отделение математики, Кафедра теории вероятностей
- обязательная, вариативной части, лекции, 36 часов
- Автор: Лебедев А.В.
- 1 сентября 2013 – 31 декабря 2013 Лебедев Алексей Викторович
-
МГУ имени М.
 В. Ломоносова, Механико-математический факультет, Отделение математики, Кафедра теории вероятностей
В. Ломоносова, Механико-математический факультет, Отделение математики, Кафедра теории вероятностей
- обязательная, вариативной части, семинары, 36 часов
- Автор: Лебедев А.В.
- 1 сентября 2012 – 31 декабря 2012 Лебедев Алексей Викторович
- МГУ имени М.В. Ломоносова, Механико-математический факультет, Отделение математики, Кафедра теории вероятностей
- обязательная, вариативной части, семинары, 36 часов
- Автор: Лебедев А.В.
- 1 сентября 2012 – 31 декабря 2012 Лебедев Алексей Викторович
-
МГУ имени М.
 В. Ломоносова, Механико-математический факультет, Отделение математики, Кафедра теории вероятностей
В. Ломоносова, Механико-математический факультет, Отделение математики, Кафедра теории вероятностей
- обязательная, вариативной части, лекции, 36 часов
- Автор: Лебедев А.В.
- 1 сентября 2011 – 31 декабря 2011 Лебедев Алексей Викторович
- МГУ имени М.В. Ломоносова, Механико-математический факультет, Отделение математики, Кафедра теории вероятностей
- обязательная, вариативной части, лекции, 36 часов
- Автор: Лебедев А.В.
- 1 сентября 2011 – 31 декабря 2011 Лебедев Алексей Викторович
-
МГУ имени М.
 В. Ломоносова, Механико-математический факультет, Отделение математики, Кафедра теории вероятностей
В. Ломоносова, Механико-математический факультет, Отделение математики, Кафедра теории вероятностей
- обязательная, вариативной части, семинары, 36 часов
- Автор: Лебедев А.В.
- 1 сентября 2010 – 31 декабря 2010 Лебедев Алексей Викторович
- МГУ имени М.В. Ломоносова, Механико-математический факультет, Отделение математики, Кафедра теории вероятностей
- обязательная, вариативной части, лекции, 36 часов
- Автор: Лебедев А.В.
- 1 сентября 2010 – 31 декабря 2010 Лебедев Алексей Викторович
-
МГУ имени М.
 В. Ломоносова, Механико-математический факультет, Отделение математики, Кафедра теории вероятностей
В. Ломоносова, Механико-математический факультет, Отделение математики, Кафедра теории вероятностей
- обязательная, вариативной части, семинары, 36 часов
- Автор: Лебедев А.В.
Педагогический дизайн: задачи, этапы и модели
Педагогический дизайн (Instructional design, ID) — относительно новое понятие в современной системе образования. Потребность в формировании качественных знаний постоянно растет, в то время как традиционные инструменты подходят для относительно простых, «линейных» методов подготовки.
При создании более сложных программ применение традиционных методов ведет к потерям времени и ресурсов. В итоге появилось понятие педагогического дизайна — дисциплины, которую команды разработчиков применяют еще на стадии проектирования, создания и оценки обучающих материалов. В его основу положено систематическое использование знаний об эффективной работе, выстраивании учебного процесса с «открытой архитектурой» и создании настоящей обучающей среды.
Задачи педагогического дизайнера
Технология педагогического дизайна относительно проста. Нужно понять потребности учащихся и определить цели обучения, а затем передать знания и информацию максимально быстро, точно и эффективно. Но для этого требуется понять все предпосылки и четко задать конечные свойства продукта. А это, в свою очередь, требует планомерной и хорошо выстроенной работы, причем не одного человека, а грамотно подобранной команды разработчиков. При этом задачи педагогического дизайнера обширны и весьма непросты:
- Анализ потребностей целевой аудитории, её компетенций и ожидаемых результатов обучения.
- Определение целей и задач учебного материала.
- Анализ и структурирование материалов в соответствии с целями.
- Выбор средств и методов учебной работы.
- Создание элементов, стиля и визуального дизайна курса.
- Разработка тестов и заданий, средств контроля и сбора информации.
- Создание курса с помощью соответствующих инструментов, либо постановка задач членам команды для разработки конкретных элементов.

- Загрузка курса в систему управления обучением (Learning Management System, LMS).
- Разработка методов оценки результатов и эффективности материалов.
- Выработка решения для дальнейшего совершенствования учебного контента.
Такая четкая последовательность обеспечит качественный рост учебного материала по мере выполнения работы и отточит формы его подачи.
Принципы педагогического дизайна
Основная задача качественной и планомерной разработки учебного курса — максимально полная передача нужной информации в доступной для ученика форме. Важен не просто сам факт её предоставления — с этим неплохо справляются более простые методы. Главной задачей является именно четкое восприятие и последующее применение полученных знаний на практике. Для достижения этого в основы педагогического дизайна заложены 8 принципов американского психолога Роберта Ганье (Robert Mills Gagne), одного из основателей педагогического дизайна и автора книг по теории обучения.
- Привлечение внимания учеников, мотивация на обучение, пробуждение интереса к теме и методам.

- Объяснение целей и задач обучения. Здесь не только даётся ответ на вопрос «зачем?», но и формируется определенный уровень ожиданий от итогов самого процесса.
- Представление нового материала. Наиболее сложная часть процесса, поскольку выборочность восприятия любого нового материала свойственна человеческой психике. А это значит, что необходимо заранее предусмотреть определенные элементы, которые позволят удержать внимание ученика на важных моментах и довести до него главную мысль проекта в максимально доступной форме.
- Сопровождение обучения. По сути это руководство учениками и семантическое формирование установки на удержание полученного материала в долгосрочной памяти.
- Практика. Необходимо быстро, пока новые знания еще свежи, опробовать их в реальных условиях или просто подтвердить соответствующим экспериментом, что четко и весьма эффективно увяжет теорию и приложение знаний.
- Обратная связь. Оценка выбранного метода обучения и его эффективности невозможна без оперативного анализа. Поэтому еще на этапе разработки курса должна закладываться максимально гибкая система обратной связи (здесь пригодятся результаты анализа целевой аудитории и её возможностей).
- Оценка успеваемости и общая оценка эффективности учебного курса.
- Перевод в практическую плоскость, помощь ученикам в сохранении знаний и их правильном применении.В отличие от пятого принципа, здесь важно перенести практические навыки в новые условия, не заданные изначальными рамками курса. Это позволит оценить глубину усвоения знаний.
5 этапов разработки учебных материалов
Процесс проектирования учебных материалов по многим параметрам схож с такими дисциплинами как программирование, логистика, дизайн и прикладная психология. Это последовательность четко определенных процедур, которые сгруппированы в ряд этапов и имеют конкретные задачи и методы их решения. Чаще всего при разработке педагогического дизайна урока используется хорошо зарекомендовавшая себя модель ADDIE (Analysis, Design, Development, Implementation, Evaluation), разбивающая весь процесс на 5 этапов.
1. Анализ
Самая важная стадия разработки: выделяются ключевые элементы, изучаются потребности учеников и задача учителя, формулируются измеримые и понятные цели обучения, оценивается целевая аудитория и формы работы с ней, а также составляется список ожидаемых результатов. Для повышения эффективности эта стадия также разбивается на несколько этапов, позволяющих за счет постепенного выявления ключевых точек четко сформулировать задачи. Тщательно проработанные цели помогают определить инструментарий учебного курса, степень его наполнения интерактивными элементами и применимость уже имеющихся материалов и методик.
Здесь же можно четко определить методики оценки эффективности самого процесса обучения. Явно и точно заданные ожидаемые результаты позволят четко сформулировать содержание и форму упражнений, контрольных вопросов, итоговых заданий и формы их подачи. А также дадут возможность сравнить между собой материалы и методики различных авторов, выбрав только максимально подходящие. Это поможет и самому ученику в процессе обучения, сконцентрирует внимание на сути предлагаемого материала и направит усилия на достижение целей.
После того как выполнен анализ, цели обучения можно уточнить, что даст возможность приступить к разработке собственно учебных материалов.
2. Проектирование
Самая обширная и непредсказуемая стадия проекта. В этот момент необходимо учесть все выводы стадии анализа и выработать общий план и структуру материала, оформить схему упражнений и оценок, визуальный ряд, интерфейс и общий дизайн, увязать между собой десятки порой сильно различающихся компонентов. По сути создается некий прототип, сценарий всего проекта, определяющий влияние каждого элемента на задачи, выявленные на первом этапе. Он также должен быть разбит на несколько шагов, поскольку попытка решить все задачи без планомерного подхода чаще всего обречена на провал.
- Выбор средств обучения. Здесь все также начинается с анализа и изучения целевой аудитории, ожидаемых условий и форм обучения, содержания материалов и применимости к ним тех или иных методов демонстрации. Затем можно приступать к детализации учебных задач и уточнению инструментария, а также выявлению необходимых знаний, умений и навыков, позволяющих выполнить все задачи курса.
- Создание сценария или план-схемы будущих учебных материалов, оформление и утверждение внешнего вида типовых экранов, проработка рабочих макетов разных фрагментов и экспертная оценка каждого элемента. Главное на этом этапе — уточнение технических требований к будущему курсу.
- Подготовка пробной версии учебных материалов, подбор или создание иллюстраций, анимационных эффектов и интерактивных элементов, аудио- или видеоряда. На этом этапе можно выявить отдельные недочеты, быстро исправить их и оперативно внести изменения в рабочий сценарий.
- Оценка и доработка материалов с точки зрения полного соответствия задачам. Здесь максимально эффективны сторонняя экспертиза и все виды моделирования: от педагогического эксперимента с обучением тестовой группы до мозгового штурма по выявлению сильных и слабых сторон разработанного продукта.
- Сопровождение и развитие учебных материалов. На этом шаге уже можно сосредоточиться на решении мелких технических вопросов, возникающих по ходу создания и тестирования, дополнять и расширять удачные модули, выявлять логические связки, готовить выход новых версий или создавать новые учебные курсы с использованием имеющихся наработок.
3. Разработка
Основная «техническая» стадия любого проекта, когда все созданные материалы занимают свое место в общей структуре, обрастают новыми элементами и логическими связями, проходят отладку и «притирку» между собой. Здесь же можно очень тонко настроить выбор методов изложения материала, тона подачи, стиля, форму изложения отдельных элементов исходя из целей всего проекта и особенностей аудитории.
На этом этапе окончательно встраиваются элементы общего контента, подбираются наиболее эффективные упражнения, вырабатываются формы обратной связи и проверки освоения материала (задания и способы контроля), оттачиваются интерфейс и связки (правила перехода) между отдельными темами или вопросами. Особое внимание следует уделить четкому определению инструментария для подведения итогов проверки или практической работы, что позволит оценить эффективность всего курса. Этап разработки — это очень кропотливая, но творческая работа, требующая от создателей максимальной гибкости при выполнении жестких исходных установок.
4. Реализация
На этой стадии учебный курс загружается в в соответствующую систему управления обучением (Learning Management System, LMS) или на ресурс, с помощью которого ученики могут получить доступ к материалам. Несмотря на казалось бы малую значимость этой стадии, она позволяет оценить применимость учебных материалов на практике. Именно здесь можно проверить, подходит ли урок или курс для выбранной аудитории, получить первичные данные о его выполнении и эффективности, наладить связь с сообществом обучающихся, что даст дополнительный материал для подготовки инструкций, сопроводительных документов и так далее.
5. Оценка
После накопления первичной информации о выполнении учебного курса нужно оценить его эффективность. Необходимо соотнести поставленные на стадии анализа задачи с результатами, которые получены на практике. Оцениваются сами учебные материалы, достижение целей обучения, выполнимость того или иного типа заданий и их соответствие общей задаче. На основании этого дорабатывается курс в целом или отдельные уроки, оцениваются результаты учебной работы и намечаются пути корректировки учебных материалов. Эта стадия в идеале должна закончиться пересмотром требований к отдельным блокам и обновленной версией всего курса.
Другие модели педагогического дизайна
ADDIE
ADDIE в настоящее время считается практически стандартом разработки учебных курсов с использованием правил педагогического дизайна. Её логичность и хорошо просматриваемая связь с классическими методами дает массу преимуществ. Есть и другие методики, вроде SAM, ALD, Dick & Carey Systems Approach Model или Jerrold Kemp Instructional Design Model, но пока они используются менее интенсивно.
Появление новых подходов легко объяснимо — растет объем информации, что увеличивает сложность линейного планирования, происходит смещение интереса разработчиков и потребителей. Поэтому подходы, ориентированные на явно заданные цели, все чаще уступают место конструктивистским моделям обучения. Это позволяет упростить процедуры педагогического дизайна и включить в них элементы кооперации и рефлексии, технологии быстрого прототипирования, каскадную модель и прочие методики. Процедура анализа, например, может длиться на протяжении всей разработки. Подготовка проектной документации сливается с фазой разработки материала. Даже доводка продукции вполне допустима на стадии окончательно работоспособной версии, «на площадке пользователя», что очень похоже на современные методики создания компьютерных программ с их бесконечными патчами и релизами.
Таким образом, жесткая последовательная цепочка производственных этапов превращается в единый процесс со множеством итераций. Грань между проектированием и производством материалов постепенно стирается, а сами они начинают взаимодействовать между собой по гораздо большему количеству смысловых или логических связок. Это дает разработчикам возможность создания весьма сложных комплексов учебных материалов.
SAM
Один из ярких примеров — модель SAM (Successive Approximation Model, Последовательная модель приближения). Её суть не в планомерном линейном развитии проекта, а в сочетании выполнения небольших по содержимому, по постоянно повторяющихся циклов разработки. Каждый из них постепенно приближает к выполнению общей задачи за счет все большей концентрации усилий по мере прохождения циклов. Это позволяет создать даже очень масштабные проекты «малыми шагами», разрабатывая каждый компонент максимально быстро и просто, поэтапно нарабатывая элементы взаимной привязки в процессе. Однако и здесь обязательно используется логичная цепочка развития, а весь процесс делится на четыре основные стадии:
- Подготовка (Preparation) — сбор информации и создание первичной базы данных по всему объему материала, который будет изучаться посредством итогового продукта. Подразумевается, что эта стадия должна быть очень быстрой, хотя на практике это далеко не так.
- Цикличная разработка (Iterative Design) — по сути мозговой штурм всех участников проекта, позволяющий быстро наработать сначала основу, а затем за счет создания все новых и новых логических блоков нарастить общий объем материала.
- Цикличное развитие (Iterative Development) — постоянное расширение материала за счет новых блоков, встраивание его в общую структуру и оценка полученных результатов.
- Карта действия (Action Mapping) — быстрый и эффективный визуальный способ проектирования. По сути это моделирование действий человека в процессе обучения, изучающее его действия в незнакомой среде. Её главными инструментами являются поиск наилучшего пути решения проблемы, создание стимулирующих, а не информационных материалов, включение в процесс изучения интуиции и экспертная оценка итогов. Проектировщик не создает «карту» самостоятельно, с самого начала над ней работают и обучающийся (пока еще в рамках модели), и эксперт. Поэтому на данном этапе также необходим тщательный анализ, как и во время предварительной проработки проекта.
Такая методика явно ориентирована не на академическую среду, а на профессионально-техническое образование и корпоративный сегмент, где относительно легко установить измеримую цель и проанализировать степень её достижения. Процесс сосредотачивается именно на конкретных навыках, а не на общем объеме знаний, что предъявляет повышенные требования к практическому опыту самих разработчиков. Все элементы итогового продукта должны строго оправдывать свое существование, выполняя непосредственно поставленные задачи и отсекая все лишнее. В этом наблюдается явное сходство с методологией SMART.
SMART
SMART – система проектного управления, базирующаяся на четко сформулированных и измеримых целях. Её суть заложена в самом названии — Specific (Конкретный), Measurable (Измеримый), Attainable (Достижимый), Relevant (Актуальный) и Time-bound (Ограниченный во времени), вместе — SMART (Умный). То есть цель непременно должна быть конкретной, измеримой, достижимой, значимой и соотноситься с конкретным сроком. А скорость и эффективность выполнения задачи зависит от правильной её формулировки. Причем каким образом будет достигнуто выполнение, не имеет особого значения. Это может быть и поэтапное и планомерное повышение результатов за счёт множества небольших шагов, и сразу ориентация на максимально возможный результат — главное, чтобы он был конкретно и объективно измерим. Предварительный анализ и планирование путей здесь также играют колоссальную роль, поэтому эта концепция применима и к педагогическому дизайну в целом.
ALD
Методика ALD (Agile Learning Design) делает акцент на скорости, гибкости и кооперативности разработки. Она вобрала в себя множество наработок из области создания программного обеспечения, главный её козырь — ускорение повышения квалификации за счет резкого увеличения концентрации на специфических задачах. Поэтому она всё чаще находит свое место в создании систем дистанционного обучения и переподготовки, где необходима интенсивная передача материала и использование активного интереса самого обучающегося.
Основные принципы методики ALD:
- Диалоговая подача материала с постоянной повторной проработкой ключевых моментов для закрепления.
- Применение шаблонов и других стандартных инструментов для быстрого и эффективного выполнения задачи.
- Активное использование интереса обучающегося и его стимулирование.
- Приоритет подачи ключевых моментов над второстепенными.
- Активное привлечение экспертов в узких областях знаний.
- Создание интерактивных баз данных со всем справочным материалом как по самой теме, так и по близким дисциплинам.
- Концентрация на самом процессе обучения и материале, а не на планировании.
- Систематическая оценка процесса обучения и потребностей ученика на каждом этапе.
В итоге создание и использование учебных материалов приобретает еще более конкретный вид, а лишние на данном этапе массивы знаний отсеиваются. Однако это вовсе не означат примитивизации процесса — в любое время все необходимые данные могут быть использованы по назначению. Причем как по мере готовности ученика, так и при появлении новых задач, что придает системе ALD большую гибкость при высокой концентрации на процессе.
Заключение
Споры об эффективности методик можно вести бесконечно. Однако хорошо заметно, что каждая из них имеет четкую ориентацию на конкретный сегмент, а потому все сильные и слабые стороны жестко связаны с самой потребностью выстраивать обучение различных групп с учетом их специфических потребностей. Хорошо освоенная и проработанная методика ADDIE даст мощный инструментарий для создания универсальных обучающих курсов, ориентированных по получение фундаментальных знаний, но требует очень высокой квалификации разработчиков. SAM позволяет объективно ускорить и упростить процесс разработки, а также придать ему большую гибкость в случае появления новых задач. А технологии ALD дают возможность быстро и четко создавать узкоспециализированные курсы, ориентированные на специальные области знаний.
Если вам понравилась статья, дайте нам знать — нажмите кнопку Поделиться.
А если у вас есть идеи для полезных статей на тему электронного обучения — напишите нам в комментариях, и мы будем рады поработать над новым материалом. 14-дневная пробная версия
учебные стоматологические модели для обучения стоматологов // Смотрим
26 июля 2022, 08:30
Хотите принять участие в программе? Достаточно заполнить форму
- общество
- музыка
- шоу
- публицистика
- искусство
- радио
- Сергей Стиллавин
- история
- медицина
- тест-драйв
- радиопередача
- путешествия
- Радио Маяк
- История (Радио Маяк)
- Музыка (Радио Маяк)
- Популярные шоу (Радио Маяк)
- Жизнь (Радио “Маяк”)
- В эфире (Радио “Маяк”)
-
Смотрим всё
Что такое обучение модели | Oden Technologies
Индустрия 4.
0 Глоссарий - 01Что такое обучение модели?
- 02Что такое обучение модели в машинном обучении
- 03Создание модели в машинном обучении
- 04Сколько времени занимает обучение модели машинного обучения?
Модель обучения машинного обучения — это процесс, в котором алгоритм машинного обучения (МО) получает достаточно обучающих данных для обучения.
Модели машинного обучения могут быть обучены для использования в производственных процессах несколькими способами. Способность моделей машинного обучения обрабатывать большие объемы данных может помочь производителям выявлять аномалии и тестировать корреляции при поиске закономерностей в потоке данных. Он может предоставить производителям возможности профилактического обслуживания и свести к минимуму запланированные и незапланированные простои.
Что такое обучение модели в машинном обучении?
Модель обучения — это набор данных, который используется для обучения алгоритма машинного обучения. Он состоит из выборочных выходных данных и соответствующих наборов входных данных, влияющих на результат. Модель обучения используется для пропуска входных данных через алгоритм, чтобы сопоставить обработанный вывод с образцом вывода. Результат этой корреляции используется для модификации модели.
Этот повторяющийся процесс называется «подгонка модели». Точность набора обучающих данных или набора данных проверки имеет решающее значение для точности модели.
Обучение модели на машинном языке — это процесс подачи в алгоритм машинного обучения данных, помогающих идентифицировать и изучать правильные значения всех задействованных атрибутов. Существует несколько типов моделей машинного обучения, наиболее распространенными из которых являются контролируемое и неконтролируемое обучение.
Обучение с учителем возможно, когда обучающие данные содержат как входные, так и выходные значения. Каждый набор данных, который имеет входы и ожидаемый результат, называется контрольным сигналом. Обучение выполняется на основе отклонения обработанного результата от задокументированного результата при подаче входных данных в модель.
Неконтролируемое обучение включает определение закономерностей в данных. Дополнительные данные затем используются для подбора шаблонов или кластеров. Это также итеративный процесс, который повышает точность на основе корреляции с ожидаемыми шаблонами или кластерами. В этом методе нет эталонного набора выходных данных.
Создание модели в машинном обучении
Создание модели машинного обучения состоит из 7 основных шагов. Вот краткий обзор каждого из этих шагов:
Определение проблемы
Определение постановки задачи — это первый шаг к определению того, чего должна достичь модель ML. Этот шаг также позволяет распознавать соответствующие входы и соответствующие им выходы; Такие вопросы, как «какова основная цель?», «какие входные данные?» и «что модель пытается предсказать?» необходимо ответить на этом этапе.
Сбор данных
После определения постановки задачи необходимо исследовать и собрать данные, которые можно использовать для питания машины. Это важный этап в процессе создания модели машинного обучения, поскольку количество и качество используемых данных будут определять, насколько эффективной будет модель. Данные можно собирать из уже существующих баз данных или создавать с нуля
Подготовка данных
Этап подготовки данных состоит в том, что данные профилируются, форматируются и структурируются по мере необходимости, чтобы подготовить их для обучения модели. На этом этапе выбираются соответствующие характеристики и атрибуты данных. Этот этап, вероятно, окажет прямое влияние на время выполнения и результаты. Это также на этапе, когда данные делятся на две группы: одна для обучения модели машинного обучения, а другая для оценки модели. На этом этапе также осуществляется предварительная обработка данных путем нормализации, устранения дубликатов и исправления ошибок.
Назначение подходящей модели/протоколов
Выбор и назначение модели или протокола должны выполняться в соответствии с целью, для достижения которой предназначена модель ML. Есть несколько моделей на выбор, таких как линейная регрессия, k-средних и байесовская. Выбор моделей во многом зависит от типа используемых данных. Например, сверточные нейронные сети для обработки изображений были бы идеальным выбором, а k-средние лучше всего работали бы для сегментации.
Обучение модели машины или «Обучение модели»
Это этап, на котором алгоритм машинного обучения обучается путем подачи наборов данных. Это этап, на котором происходит обучение. Последовательное обучение может значительно улучшить скорость прогнозирования модели ML. Веса модели должны быть инициализированы случайным образом. Таким образом, алгоритм научится соответствующим образом корректировать веса.
Оценка и определение критерия успеха
Модель машины должна быть протестирована на соответствие «проверочному набору данных». Это помогает оценить точность модели. Определение мер успеха на основе того, для чего предназначена модель, имеет решающее значение для обоснования корреляции.
Настройка параметров
Выбор правильного параметра, который будет изменен для воздействия на модель машинного обучения, является ключом к достижению точной корреляции. Набор параметров, которые выбираются на основе их влияния на архитектуру модели, называются гиперпараметрами. Процесс определения гиперпараметров путем настройки модели называется настройкой параметров. Параметры корреляции должны быть четко определены таким образом, чтобы точка убывающей отдачи для проверки была как можно ближе к 100% точности.
Сколько времени занимает обучение модели машинного обучения?
Для обучения модели машинного обучения не существует определенного периода или предустановленного набора итераций. Факторами, влияющими на продолжительность обучения, могут быть качество обучающих данных, правильное определение мер успеха и сложность выбора модели. Такие факторы, как метод обучения, распределение весов и сложность модели, также играют важную роль. Другие факторы, не относящиеся к данным или моделям, такие как вычислительная мощность и квалифицированные ресурсы, также могут влиять на продолжительность обучения. Всегда есть возможность оптимизировать обучение модели, поскольку количество параметров, влияющих на ее продолжительность, слишком велико.
Корпоративные модели обучения в области обучения и развития — Модели обучения и развития
Джейн Харт, директор и редактор Центра современного обучения на рабочем месте, недавно написала статью об опросе, который она проводит по ценным способам обучения на рабочем месте. Ее результаты показывают, что формальные мероприятия, предлагаемые большинством организаций обучения и развития (например, электронное обучение, конференции, аудиторные занятия), на самом деле считаются наименее ценными для развития учащихся. Удивительно, правда? Фактически, в то время как отделы обучения и развития обычно сосредотачиваются на создании более привлекательных и интерактивных учебных курсов, Харт показывает, что на самом деле сотрудники хотят более актуальный, современный подход , включающий ежедневный рабочий опыт , обмен знаниями с командами , веб-ресурсы , профессиональные сети и сообщества , и отзывы наставников в программы.
Почему именно эти методы имеют более высокий рейтинг?
Как наиболее ценный метод обучения, ежедневный рабочий опыт имеет решающее значение для обучения сотрудников, поскольку он позволяет сотрудникам практиковать и применять полученные навыки в реальном мире, а также участвовать в непрерывном обучении, а не в эпизодическом обучении. Кроме того, личное ежедневное взаимодействие предоставляет возможности для социального обучения, которое помогает развивать все более важные социальные навыки на рабочем месте, такие как общение, лидерство и работа в команде.
Обмен знаниями в вашей команде расширяет возможности обучения, облегчая контекстно-зависимое обучение и обеспечивая более глубокое обучение. В конце концов, только сначала обдумав и переоценив свои мысли, люди могут затем воплотить их в жизнь и поделиться ими целостным и всеобъемлющим образом.
Аналогичным образом, получение обратной связи позволяет учащимся получить доступ к ценным знаниям не только от своих опытных наставников, но и от своих сверстников. Обратная связь со сверстниками может быть даже более действенной, чем обратная связь от экспертов, отчасти потому, что новые учащиеся могут лучше объяснять понятия другим учащимся, а отчасти потому, что социальные связи (в том числе профессиональные сети и сообщества ) привносят социальные связи и подкрепление в динамику обучения (узнайте, как оптимизировать обратную связь на онлайн-курсах). Кроме того, Харт указывает, что ключевой особенностью, которая делает этот конкретный аспект успешным, является то, что они выбираются и организуются самими работниками. Этот акт самоотбора и самоорганизации поощряет самодостаточность в непрерывном обучении, что является важным навыком, который необходимо развивать в контексте постоянно меняющегося рабочего ландшафта.
«Хотя некоторые все еще могут считать, что обучение на рабочем месте — это то, что должно быть организовано и управляемо L&D, не менее важно сосредоточиться на том, чтобы помочь людям стать более самостоятельными и самодостаточными людьми, которые учатся у самых разных источников: контент, люди, события и опыт — как внутри, так и за пределами их организации» — Джейн Харт
Современный корпоративный тренинг на платформе НовоЭд
Эти высокоценные способы обучения можно поощрять различными способами в организациях. Что касается онлайн-обучения, учебная платформа NovoEd была создана специально для того, чтобы сочетать формальное традиционное электронное обучение с более эффективными подходами к обучению по принципу «равный-равному», выявленным в ходе опроса. Это включает в себя включение реальных проектов на рабочем месте ( основанное на проектах экспериментальное обучение показало, что оно улучшает долгосрочное запоминание контента, а также улучшает навыки решения проблем и совместной работы, Strobel and van Barneveld, 2009) и обучение в небольших группах, что обеспечивает преимущества социального обучения для его участников за счет расширения их профессиональной сети и сообщества , снижения показателей отсева и улучшения навыков общения и сотрудничества (Springer, Stanne, and Donovan, 1999).
Действительно, с быстрым темпом технологического роста мир труда постоянно развивается, и каждому необходимо обладать мышлением роста для постоянного самосовершенствования и саморазвития, чтобы выжить и процветать в этом новом мире. . Люди с таким мышлением любят учиться, и эти современные учащиеся все чаще переносят свое обучение в онлайн. Включив социальный обмен проектами и отзывами, мы можем выйти за рамки стандартной функциональности LMS и способствовать неформальному обучению и взаимодействию с коллегами, что приводит к действительно эффективному обучению на современном рабочем месте.
Зарегистрируйтесь для участия в нашем предстоящем интерактивном туре по продукту, а также в разделе вопросов и ответов , чтобы узнать, как NovoEd позволяет масштабировать лучшее очное онлайн-обучение для сотрудников по всему миру и повышает влияние обучения на ваши бизнес-инициативы.
Если вам понравился этот материал, обязательно ознакомьтесь с другими нашими публикациями о сообществах онлайн-обучения, командных организациях, онлайн-курсах наставничества и формальных и неформальных отзывах.
Похожие запросы
Решения для корпоративного обучения, обучение устойчивому развитию, программа развития лидерства GE, стратегии корпоративного обучения
Хотите больше от НовоЭд? Подпишитесь на наш блог сегодня.
VGhhbmsgeW91IGZvciBzdWJzY3JpYmluZy4=
Похожие сообщения в блоге
Блог
Прочитай сейчас
СтрелкаБлог
Платформы обучения: что такое LXP?
Что такое платформа обучения? Мы рассматриваем примеры обучения как LMS, так и LXP, а также третий вариант сочетания и развития лучшего из обоих.
Прочитай сейчас
СтрелкаБлог
Прочитай сейчас
СтрелкаБлог
Прочитай сейчас
СтрелкаБлог
Прочитай сейчас
СтрелкаБлог
Прочитай сейчас
СтрелаTraining Models — документация h3O 3.38.0.1
h3O поддерживает обучение моделей с учителем (где переменная результата известна) и моделей без учителя (немаркированные данные). Ниже мы приводим примеры классификации, регрессии, кластеризации, уменьшения размерности и обучения на сегментах данных (обучаем набор моделей — по одной для каждого раздела данных).
Обучение с учителем
Алгоритмы обучения с учителем поддерживают задачи классификации и регрессии.
Классификация и регрессия
В задачах классификации выходная или «ответная» переменная является категориальным значением. Ответ может быть бинарным (например, да/нет) или мультиклассовым (например, собака/кошка/мышь).
В задачах регрессии выходная переменная или переменная «отклик» представляет собой числовое значение. Примером может служить предсказание чьего-то возраста или продажной цены дома.
Классификация и регрессия в моделях h3O : Способ, которым вы сообщаете h3O, хотите ли вы выполнить классификацию или регрессию для конкретного контролируемого алгоритма, заключается в кодировании столбца ответа либо как категориальный/факторный тип (классификация), либо как числовой тип. (регрессия). Если ваш столбец представлен в виде строк («да», «нет»), то h3O автоматически закодирует этот столбец как категориальный/факторный тип (также известный как «перечисление») при импорте набора данных. Однако, если у вас есть столбец с целыми числами, который представляет класс в задаче классификации (0, 1), вам придется изменить тип столбца с числового на категориальный/факторный (также известный как «перечисление»). Причина, по которой h3O требует, чтобы столбец ответа был закодирован как «правильный» тип для конкретной задачи, заключается в максимальной эффективности алгоритма.
Пример классификации
В этом примере используется набор данных Prostate и алгоритм GLM h3O для прогнозирования вероятности того, что у пациента будет диагностирован рак простаты. Набор данных включает следующие столбцы:
-
ID : Идентификатор строки. Его можно исключить из списка предикторов.
-
КАПСУЛА : проникла ли опухоль в капсулу предстательной железы
-
ВОЗРАСТ : Возраст пациента 9 лет0005
-
РАССА : Раса пациента
-
DPROS : Результат пальцевого ректального исследования, где 1 = узел отсутствует; 2 = однодольный узел слева; 3 = односторонний узел справа; и 4 = билобарный узел.
-
DCAPS : Имелось ли поражение капсулы при ректальном исследовании
-
ПСА : Уровень специфического антигена простаты (мг/мл)
-
ТОМ : Объем опухоли (см3)
-
GLEASON : Оценка пациента по шкале Глисона в диапазоне от 0 до 10
В этом примере для прогнозирования используются только столбцы AGE, RACE, VOL и GLEASON.
Python
библиотека (h3o)
h3o.init()
# импортируем набор данных простаты
df <- h3o.importFile("https://h3o-public-test-data.s3.amazonaws.com/smalldata/prostate/prostate.csv")
# преобразовать столбцы в множители
df$CAPSULE <- as.factor(df$CAPSULE)
df$RACE <- as.factor(df$RACE)
df$DCAPS <- as.factor(df$DCAPS)
df$DPROS <- as.factor(df$DPROS)
# установить столбцы предиктора и ответа
предикторы <- c("ВОЗРАСТ", "РАС", "ОБЪЕМ", "ГЛИСОН")
ответ <- "КАПСУЛА"
# разделить набор данных на обучающий и тестовый наборы
df_splits <- h3o. splitFrame (данные = df, ratios = 0,8, seed = 1234)
поезд <- df_splits[[1]]
тест <- df_splits[[2]]
# построить модель GLM
prostate_glm <- h3o.glm(family = "биномиальный",
х = предикторы,
у = ответ,
тренировочный_кадр = дф,
лямбда = 0,
вычисление_p_значения = ИСТИНА)
# прогнозировать, используя модель GLM и набор данных для тестирования
предсказать <- h3o.predict (объект = prostate_glm, новые данные = тест)
# просмотреть сводку прогнозов
h3o.head(предсказать)
предсказать p0 p1 StdErr
1 1 0,5318993 0,46810066 0,4472349
2 0 0,7269800 0,27302003 0,4413739
3 0 0,76 0,098 0,3528526
4 0 0,37 0,09370628 0,2874410
5 1 0,6414760 0,35852398 0,2719742
6 1 0,5092692 0,480 0,4007240
импорт воды
h3o.init()
из h3o.estimators.glm импортировать h3OGeneralizedLinearEstimator
# импортируем набор данных простаты
простата = h3o.import_file("https://h3o-public-test-data. s3.amazonaws.com/smalldata/prostate/prostate.csv")
# преобразовать столбцы в множители
простата['КАПСУЛА'] = простата['КАПСУЛА'].asfactor()
простата['ГОНКА'] = простата['ГОНКА'].asfactor()
простата['DCAPS'] = простата['DCAPS'].asfactor()
простата['DPROS'] = простата['DPROS'].asfactor()
# установить столбцы предиктора и ответа
предикторы = ["ВОЗРАСТ", "ГОНКА", "ОБЪЕМ", "ГЛИСОН"]
response_col = "КАПСУЛА"
# разделить на наборы для обучения и тестирования
поезд, тест = prostate.split_frame (соотношения = [0,8], начальное число = 1234)
# установить параметры моделирования GLM
# и инициализируем обучение модели
glm_model = h3OGeneralizedLinearEstimator(family= "биномиальный",
лямбда_ = 0,
calculate_p_values = Истина)
glm_model.train (предикторы, response_col, training_frame = простата)
# предсказать, используя модель и набор данных для тестирования
предсказать = glm_model.predict (тест)
# Просмотр сводки прогноза
предсказать. head()
предсказать p0 p1 StdErr
--------- -------- --------- --------
1 0,531899 0,468101 0,447235
0 0,72698 0,27302 0,441374
0 0,8 0,09 0,352853
0 0,4 0,0937063 0,287441
1 0,641476 0,358524 0,271974
1 0,509269 0,4Пример регрессии
В этом примере используются данные Boston Housing и алгоритм GLM h3O для прогнозирования средней цены дома с использованием всех доступных функций. Набор данных включает следующие столбцы:
-
преступность : Уровень преступности на душу населения по городам
-
zn : Доля жилых земель, зонированных под участки площадью более 25 000 кв. футов
-
indus : Доля неторговых площадей в акрах на город
-
час : фиктивная переменная реки Чарльз (1, если участок ограничивает реку Чарльз; 0 в противном случае)
-
nox : Концентрация оксидов азота (частей на 10 миллионов)
-
п.
м. : Среднее количество комнат в жилом помещении -
Возраст : Доля домов, построенных до 1940 года
-
dis : Взвешенные расстояния до пяти центров занятости Бостона
-
рад : Индекс доступности радиальных магистралей
-
налог : Полная ставка налога на имущество за 10 000 долларов США
- 92, где Bk — доля чернокожего населения
-
lstat : Низкий статус населения в %
-
medv : Средняя стоимость домов, занимаемых владельцами, в 1000 долларов США
Python
библиотека (h3o) h3o.init() # импортируем бостонский набор данных: # этот набор данных рассматривает особенности пригородов Бостона и прогнозирует средние цены на жилье # исходный набор данных можно найти по адресу https://archive.ics.uci.edu/ml/datasets/Housing бостон <- h3o.
импорт воды
из h3o.estimators.glm импортировать h3OGeneralizedLinearEstimator
h3o.init()
# импортируем бостонский набор данных:
# этот набор данных рассматривает особенности пригородов Бостона и прогнозирует средние цены на жилье
# исходный набор данных можно найти по адресу https://archive.ics.uci.edu/ml/datasets/Housing
бостон = h3o.import_file("https://s3.amazonaws.com/h3o-public-test-data/smalldata/gbm_test/BostonHousing.csv")
# устанавливаем столбцы-предикторы
предикторы = boston.columns[:-1]
# этот пример будет предсказывать столбец medv
# вы можете запустить следующее, чтобы увидеть, что medv действительно является числовым значением
бостон["медв"].isnumeric()
[Истинный]
# установите столбец ответа на «medv», что является средней стоимостью домов, занимаемых владельцами, в 1000 долларов.
ответ = "медв"
# преобразовать столбец `chas` в коэффициент
# `chas` = фиктивная переменная Charles River (= 1, если участок ограничивает реку; 0 в противном случае)
бостон['час'] = бостон['час'].asfactor()
# разделить на наборы для обучения и тестирования
поезд, тест = boston.split_frame(соотношения = [0,8], начальное число = 1234)
# установить параметр `альфа` на 0,25
# затем инициализируем оценщик, затем обучаем модель
boston_glm = h3OОбобщенный линейный оценщик (альфа = 0,25)
boston_glm.train(x = предикторы,
у = ответ,
training_frame = поезд)
# предсказать, используя модель и набор данных для тестирования
предсказать = boston_glm.predict (тест)
# Просмотр сводки прогноза
предсказать.head()
предсказывать
---------
28.2943
19.4569
19.0823
16.9093
16.2314
18.2361
12.6945
17.5583
15.4797
20,7294
[10 строк х 1 столбец]
Обучение без учителя
Алгоритмы обучения без учителя включают методы кластеризации и обнаружения аномалий. Алгоритмы обучения без учителя, такие как GLRM и PCA, также могут использоваться для уменьшения размерности.
Пример кластеризации
В приведенном ниже примере используется алгоритм K-средних для построения простой модели кластеризации набора данных Iris.
Питон
библиотека (h3o)
h3o.init()
# Импортируем набор данных iris в h3O:
ирис <- h3o.importFile("http://h3o-public-test-data.s3.amazonaws.com/smalldata/iris/iris_wheader.csv")
# Установить предикторы:
предикторы <- c("sepal_len", "sepal_wid", "petal_len", "petal_wid")
# Разделить набор данных на поезд и действительный набор:
iris_split <- h3o.splitFrame (данные = радужная оболочка, коэффициенты = 0,8, семя = 1234)
поезд <- iris_split[[1]]
действительный <- iris_split[[2]]
# Построить и обучить модель:
iris_kmeans <- h3o.kmeans(k = 10,
оценка_k = ИСТИНА,
стандартизировать = ЛОЖЬ,
семя = 1234,
х = предикторы,
training_frame = поезд,
validation_frame = действительный)
# Оценка производительности:
производительность <- h3o. performance(iris_kmeans)
производительность
h3OClusteringMetrics: kmeans
** По данным обучения. **
Всего внутри СС: 63,09516
Между СС: 483.8141
Всего СС: 546,9092
Статистика Центроида:
размер центроида внутри_кластера_суммы_из_квадратов
1 1 36.00000 11.08750
2 2 51,00000 30,78627
3 3 36.00000 21.22139
импорт воды
из h3o.estimators импортировать h3OKMeansEstimator
h3o.init()
# Импортируем набор данных iris в h3O:
iris = h3o.import_file("http://h3o-public-test-data.s3.amazonaws.com/smalldata/iris/iris_wheader.csv")
# Установить предикторы:
предикторы = ["sepal_len", "sepal_wid", "petal_len", "petal_wid"]
# Разделить набор данных на поезд и действительный набор:
поезд, действительный = iris.split_frame(соотношения=[.8], seed=1234)
# Построить и обучить модель:
iris_kmeans = h3OKMeansEstimator(k=10,
оценка_k = Верно,
стандартизировать = Ложь,
семя=1234)
iris_kmeans.train (x = предикторы,
training_frame = поезд,
validation_frame=действительный)
# Оценка производительности:
производительность = iris_kmeans. model_performance()
производительность
ModelMetricsClustering: kmeans
** Сообщается по поездным данным. **
MSE: NaN
Среднеквадратичное значение: NaN
Всего в кластере Сумма квадратов ошибок: 63,095160649
Общая сумма квадратной ошибки к среднему: 546,31233204
Между кластерной суммой квадратной ошибки: 483,8140724326029
Статистика Центроида:
размер центроида внутри_кластера_суммы_из_квадратов
-- ---------- ------ -----------------
1 36 11.0875
2 51 30,7863
3 36 21.2214
Пример обнаружения аномалий
В этом примере используется алгоритм Isolation Forest для обнаружения аномалий в наборе данных электрокардиограммы (ЭКГ).
Python
библиотека (h3o)
h3o.init()
# импортировать наборы данных разногласий по ЭКГ:
train <- h3o.importFile("http://s3.amazonaws.com/h3o-public-test-data/smalldata/anomaly/ecg_discord_train.csv")
test <- h3o.importFile("http://s3.amazonaws.com/h3o-public-test-data/smalldata/anomaly/ecg_discord_test.csv")
# тренируемся с использованием параметра `sample_size`:
isofor_model <- h3o. isolationForest (training_frame = поезд,
размер_образца = 5,
nдеревья = 7,
семя = 12345)
# проверить прогнозы и получить значение mean_length.
# mean_length — это среднее количество расщеплений, которое потребовалось для изоляции
# запись по всем деревьям решений в лесу. Рекорды
# с меньшим значением mean_length с большей вероятностью будут аномальными
# потому что для их изоляции требуется меньше разделов данных.
pred <- h3o.predict(isofor_model, тест)
пред
предсказать среднюю_длину
1 0,5555556 1,857143
2 0,5555556 1,857143
3 0,3333333 2,142857
4 1.0000000 1.285714
5 0,7777778 1,5714296 0,6666667 1,714286
[23 строки х 2 столбца]
импорт воды
из h3o.estimators.isolation_forest импортировать h3OIsolationForestEstimator
h3o.init()
# импортировать наборы данных разногласий по ЭКГ:
train = h3o.import_file("http://s3.amazonaws.com/h3o-public-test-data/smalldata/anomaly/ecg_discord_train. csv")
test = h3o.import_file("http://s3.amazonaws.com/h3o-public-test-data/smalldata/anomaly/ecg_discord_test.csv")
# построить модель, используя параметр `sample_size`:
isofor_model = h3OIsolationForestEstimator (sample_size = 5, ntrees = 7, seed = 12345)
isofor_model.train (training_frame = поезд)
# проверить прогнозы и получить значение mean_length.
# mean_length — это среднее количество расщеплений, которое потребовалось для изоляции
# запись по всем деревьям решений в лесу. Рекорды
# с меньшим значением mean_length с большей вероятностью будут аномальными
# потому что для их изоляции требуется меньше разделов данных.
пред = isofor_model.predict (тест)
пред
предсказать среднюю_длину
--------- -------------
0,555556 1,85714
0,555556 1,85714
0,333333 2,14286
1 1.28571
0,777778 1,57143
0,666667 1,714290,666667 1,71429
0 2,57143
0,888889 1,42857
0,777778 1,57143
[23 строки х 2 столбца]
Пример уменьшения размерности
Ниже приведен простой пример, показывающий, как использовать алгоритм GLRM для уменьшения размерности набора данных USArrests.
Python
библиотека (h3o)
h3o.init()
# Импортируем набор данных USArrests в h3O:
аресты <- h3o.importFile("https://s3.amazonaws.com/h3o-public-test-data/smalldata/pca_test/USArrests.csv")
# Разделить набор данных на поезд и действительный набор:
аресты_splits <- h3o.splitFrame (данные = аресты, коэффициенты = 0,8, семя = 1234)
поезд <- арестов_расколов[[1]]
действительный <- арестованные_разделения[[2]]
# Построить и обучить модель:
glrm_model = h3o.glrm (training_frame = поезд,
к = 4,
потеря = "Квадратичный",
гамма_х = 0,5,
гамма_у = 0,5,
макс_итераций = 700,
recovery_svd = ИСТИНА,
инициализация = "СВД",
преобразование = "СТАНДАРТИЗАЦИЯ")
# Оценка производительности:
аресты_перф <- h3o.performance(glrm_model)
аресты_перф
h3ODimReductionMetrics: glrm
** По данным обучения. **
Сумма квадратов ошибок (числовых): 1,983347e-13
Ошибка неправильной классификации (категория): 0
Количество цифровых записей: 144
Количество категорийных записей: 0
# Генерация прогнозов на проверочном наборе:
аресты_пред <- h3o. predict(glrm_model, newdata = действительный)
аресты_пред
reconstr_Murder reconstr_Assault reconstr_UrbanPop reconstr_Rape
1 0,2710690 0,2568493 -1,08479880 -0,281431002
2 2,3535244 0,5080499 -0,39237403 0,357493436
3 -1,3270945 -1,3460498 -0,60010146 -1,113046938
4 1,8692325 0,9626034 0,02308083 -0,007606243
5 -1,3513091 -1,0230776 -1,01555632 -1,468004959
6 0,8764339 1,5726620 0,09232330 0,560326590
[14 строк х 4 столбца]
импорт воды
из h3o.estimators импортировать h3OGeneralizedLowRankEstimator
h3o.init()
# Импортируем набор данных USArrests в h3O:
арестsh3O = h3o.import_file("https://s3.amazonaws.com/h3o-public-test-data/smalldata/pca_test/USArrests.csv")
# Разделить набор данных на поезд и действительный набор:
поезд, действительный = арестованный3O.split_frame(соотношения = [.8], начальное число = 1234)
# Построить и обучить модель:
glrm_model = h3OGeneralizedLowRankEstimator(k = 4,
потеря = «квадратичная»,
гамма_х = 0,5,
гамма_у = 0,5,
макс_итераций = 700,
recovery_svd = Истина,
инициализация = "СВД",
трансформировать = "стандартизировать")
glrm_model. train (training_frame = поезд)
# Оценка производительности
аресты_перф = glrm_model.model_performance()
аресты_перф
МодельМетриксGLRM: glrm
** Сообщается по поездным данным. **
MSE: NaN
Среднеквадратичное значение: NaN
Сумма квадратов ошибок (числовых): 1,983347263428422e-13
Ошибка неправильной классификации (категория): 0,0
# Генерация прогнозов на проверочном наборе:
пред = glrm_model.predict (действительно)
пред
reconstr_Murder reconstr_Assault reconstr_UrbanPop reconstr_Rape
------------------ ------------------ ----------------------------- ----------------
0,271069 0,256849 -1,0848 -0,281431
2,35352 0,50805 -0,392374 0,357493
-1,32709 -1,34605 -0,600101 -1,11305
1,86923 0,962603 0,0230808 -0,00760624
-1,35131 -1,02308 -1,01556 -1,468
0,876434 1,57266 0,0923233 0,560327
-0,794373 -0,23359 1,33869 -0,605964
1,07015 1,03437 0,577021 1,30067
-0,818588 -0,795801 -0,253889 -0,585681
-0,0679354 -0,113971 1,61566 -0,352423
[14 строк х 4 столбца]
Сегменты обучения
В h3O вы можете выполнять массовое обучение сегментов или разделов тренировочного набора. Метод train_segments() в Python и функция h3o.train_segments() в R обучают модель h3O для каждого сегмента (подгруппы) обучающего набора данных.
Определение сегментированной модели
Функция train_segments() принимает следующие параметры:
-
x : Список имен столбцов или индексов, указывающих столбцы-предикторы.
-
y : Индекс или имя столбца, указывающее столбец ответа.
-
алгоритм (только R): при построении сегментированной модели в R укажите используемый алгоритм. Доступные опции включают:
-
агрегатор -
коксф -
глубокое обучение -
Гам -
гбм -
глрм -
глютен -
изоляциялес -
kmeans -
наивные -
шт -
псвм -
случайный лес -
в сборе -
свд -
целевой кодер -
word2vec -
xgboost
-
-
training_frame : h3OFrame, имеющий столбцы, указанные
xиy(а также любые дополнительные столбцы, указанныеfold_column,offset_columnиweights0_column). -
offset_column : Имя или индекс столбца в
training_frame, который содержит смещения. -
fold_column : Имя или индекс столбца в
training_frame, который содержит назначения свертки для каждой строки. -
weights_column : Имя или индекс столбца в
training_frame, который содержит веса для каждой строки. -
validation_frame : h3OFrame с проверочными данными, которые будут оцениваться во время обучения.
-
max_runtime_secs : Максимально допустимое время выполнения в секундах для обучения каждой модели. Используйте 0 для отключения. Обратите внимание, что независимо от того, как задан этот параметр, для каждого входного сегмента будет построена модель. Этот параметр влияет только на обучение отдельных моделей.
-
segments (Python)/ segment_columns (R): список столбцов для сегментации.
h3O сгруппирует набор данных для обучения (и проверки) по столбцам сегментов и обучит отдельную модель для каждого сегмента (группы строк). В качестве альтернативы предоставлению списка столбцов пользователи также могут предоставить явное перечисление сегментов для построения моделей. Это перечисление должно быть представлено как h3OFrame. -
segment_models_id : Идентификатор возвращаемой коллекции моделей сегментов. Если он не указан, он будет сгенерирован автоматически.
-
параллелизм : Уровень параллелизма построения объемных сегментных моделей. Это максимальное количество моделей, которые каждый узел h3O будет создавать параллельно.
-
подробный : Включите печать дополнительной информации во время построения модели. По умолчанию имеет значение Ложь.
Пример сегментированной модели
Ниже приведен простой пример, описывающий обучение сегментированной модели. Более подробный пример доступен в демонстрации h3O Segment Model Building.
Python
библиотека (h3o)
h3o.init()
# импортируем титанический набор данных
титанический <- h3o.importFile("https://s3.amazonaws.com/h3o-public-test-data/smalldata/gbm_test/titanic.csv")
# установить столбцы предиктора и ответа
предикторы <- c("имя", "пол", "возраст", "sibsp", "parch", "билет", "тариф", "кабина")
ответ <- "выжил"
# преобразовать столбец ответа в коэффициент
титанический['выживший'] <- as.factor(титанический['выживший'])
# разделить набор данных на обучающий и проверочный наборы данных
titanic.splits <- h3o.splitFrame (данные = titanic, ratios = 0,8, seed = 1234)
поезд <- titanic.splits[[1]]
действительный <- titanic.splits[[2]]
# обучаем сегментированную модель, перебирая столбец pclass
titanic_models <- h3o.train_segments (алгоритм = "gbm",
segment_columns = "pкласс",
х = предикторы,
у = ответ,
training_frame = поезд,
validation_frame = действительный,
семя = 1234)
# преобразовать сегментированные модели в h3OFrame
as. data.frame(titanic_models)
импорт воды
из h3o.estimators.gbm импортировать h3OGradientBoostingEstimator
h3o.init()
# импортируем титанический набор данных:
titanic = h3o.import_file("https://s3.amazonaws.com/h3o-public-test-data/smalldata/gbm_test/titanic.csv")
# установить столбцы предиктора и ответа
предикторы = ["имя", "пол", "возраст", "сибсп", "парч", "билет", "тариф", "кабина"]
ответ = "выжил"
# преобразовать столбец ответа в коэффициент
титанический[ответ] = титанический[ответ].asfactor()
# разделить набор данных на обучающий и проверочный наборы данных
поезд, действительный = titanic.split_frame (соотношения = [0,8], seed = 1234)
# обучаем сегментированную модель, перебирая столбец plcass
titanic_gbm = h3OGradientBoostingEstimator (seed = 1234)
titanic_models = titanic_gbm.train_segments (сегменты = ["pclass"],
х = предикторы,
у = ответ,
training_frame = поезд,
validation_frame = действительный)
# преобразовать сегментированные модели в h3OFrame
titanic_models. as_frame()
Что это такое и почему это важно
Обучение модели машинного обучения (ML) — это процесс, в котором алгоритм машинного обучения получает обучающие данные, на основе которых он может учиться. Модели машинного обучения можно натренировать, чтобы они приносили пользу бизнесу разными способами, путем быстрой обработки огромных объемов данных, выявления закономерностей, обнаружения аномалий или проверки корреляций, которые человеку было бы трудно сделать без посторонней помощи.
Что такое обучение моделей?
Обучение модели лежит в основе жизненного цикла разработки науки о данных, где группа специалистов по обработке и анализу данных работает над подбором наилучших весов и смещений для алгоритма, чтобы минимизировать функцию потерь в диапазоне предсказания. Функции потерь определяют, как оптимизировать алгоритмы ML. Команда специалистов по данным может использовать различные типы функций потерь в зависимости от целей проекта, типа используемых данных и типа алгоритма.
Когда используется метод обучения с учителем, обучение модели создает математическое представление взаимосвязи между функциями данных и целевой меткой. При неконтролируемом обучении он создает математическое представление среди самих признаков данных.
Важность обучения модели
Обучение модели — это первичный этап машинного обучения, в результате которого создается рабочая модель, которую затем можно проверить, протестировать и развернуть. Производительность модели во время обучения в конечном итоге определит, насколько хорошо она будет работать, когда она в конечном итоге будет помещена в приложение для конечных пользователей.
Как качество обучающих данных, так и выбор алгоритма имеют решающее значение на этапе обучения модели. В большинстве случаев обучающие данные разбиваются на два набора для обучения, а затем проверки и тестирования.
Выбор алгоритма в первую очередь определяется конечным вариантом использования. Однако всегда необходимо учитывать дополнительные факторы, такие как сложность модели алгоритма, производительность, интерпретируемость, требования к компьютерным ресурсам и скорость. Уравновешивание этих различных требований может сделать выбор алгоритмов запутанным и сложным процессом.
Как обучить модель машинного обучения
Обучение модели требует систематического, повторяемого процесса, который позволяет максимально эффективно использовать имеющиеся обучающие данные и время вашей группы по обработке и анализу данных. Прежде чем приступить к этапу обучения, вам необходимо сначала определить постановку задачи, получить доступ к набору данных и очистить данные, которые будут представлены в модели.
В дополнение к этому вам необходимо определить, какие алгоритмы вы будете использовать и с какими параметрами (гиперпараметрами) они будут работать. Сделав все это, вы можете разделить свой набор данных на набор для обучения и набор для тестирования, а затем подготовить алгоритмы своей модели для обучения.
Разделить набор данных
Ваши исходные обучающие данные — это ограниченный ресурс, который необходимо распределять осторожно. Некоторые из них можно использовать для обучения вашей модели, а некоторые — для тестирования вашей модели, но вы не можете использовать одни и те же данные для каждого шага. Вы не можете должным образом протестировать модель, если не дали ей новый набор данных, с которым она раньше не сталкивалась. Разделение обучающих данных на два или более набора позволяет обучать, а затем проверять модель с использованием одного источника данных. Это позволяет вам увидеть, является ли модель переоснащенной, что означает, что она хорошо работает с обучающими данными, но плохо с тестовыми данными.
Распространенным способом разделения обучающих данных является перекрестная проверка. Например, при 10-кратной перекрестной проверке данные разбиваются на десять наборов, что позволяет обучать и тестировать данные десять раз. Для этого:
- Разделите данные на десять равных частей или сгибов.
- Назначьте одну складку в качестве удерживающей складки.
- Обучите модель остальным девяти сгибам.
- Проверьте модель на удерживающем изгибе.
Повторите этот процесс десять раз, каждый раз выбирая другую складку в качестве удерживающей складки. Средняя производительность по десяти удержанным сгибам — это ваша оценка производительности, называемая перекрёстной оценкой.
Выберите алгоритмы для тестирования
В машинном обучении есть тысячи алгоритмов на выбор, и нет надежного способа определить, какой из них будет лучшим для конкретной модели. В большинстве случаев вы, скорее всего, перепробуете десятки, если не сотни алгоритмов, чтобы найти тот, который приводит к точной рабочей модели. Выбор алгоритмов-кандидатов часто зависит от:
- Размер обучающих данных.
- Точность и интерпретируемость требуемого вывода.
- Требуемая скорость обучения, которая обратно пропорциональна точности.
- Линейность обучающих данных.
- Количество признаков в наборе данных.
Настройка гиперпараметров
Гиперпараметры — это высокоуровневые атрибуты, устанавливаемые группой по обработке и анализу данных перед сборкой и обучением модели. Хотя многие атрибуты можно узнать из обучающих данных, они не могут узнать свои собственные гиперпараметры.
Например, если вы используете алгоритм регрессии, модель может сама определить коэффициенты регрессии путем анализа данных. Однако он не может диктовать силу штрафа, который следует использовать для упорядочения переизбытка переменных. В качестве другого примера, модель, использующая метод случайного леса, может определить, где деревья решений будут разделены, но количество используемых деревьев необходимо настроить заранее.
Подгонка и настройка моделей
Теперь, когда данные подготовлены и определены гиперпараметры модели, пришло время начать обучение моделей. По сути, процесс состоит в том, чтобы перебирать различные алгоритмы, используя каждый набор значений гиперпараметров, которые вы решили изучить. Для этого:
- Разделите данные.
- Выберите алгоритм.
- Настройте значения гиперпараметров.
- Обучить модель.
- Выберите другой алгоритм и повторите шаги 3 и 4.
Затем выберите другой набор значений гиперпараметров, который вы хотите попробовать для того же алгоритма, снова проверьте его и рассчитайте новую оценку. После того, как вы попробовали каждое значение гиперпараметра, вы можете повторить те же шаги для дополнительных алгоритмов.
Воспринимайте эти испытания как легкоатлетические заезды. Каждый алгоритм продемонстрировал, что он может делать с различными значениями гиперпараметров. Теперь вы можете выбрать лучшую версию из каждого алгоритма и отправить их на финальный конкурс.
Выберите лучшую модель
Теперь пришло время протестировать лучшие версии каждого алгоритма, чтобы определить, какая из них дает вам наилучшую модель в целом.
- Делайте прогнозы на основе тестовых данных.
- Определите истину для вашей целевой переменной во время обучения этой модели.
- Определите показатели производительности на основе ваших прогнозов и целевой переменной истинности.
- Запустите каждую финалистку с тестовыми данными.
После завершения тестирования вы можете сравнить их производительность, чтобы определить, какие модели лучше. Абсолютный победитель должен был показать хорошие результаты (если не лучшие) как на тренировках, так и на тестах. Он также должен хорошо работать по другим вашим показателям производительности (таким как скорость и эмпирические потери) и, в конечном счете, должен адекватно решать или отвечать на вопрос, поставленный в постановке задачи.
Систематический подход к обучению модели
Использование систематического и воспроизводимого процесса обучения модели имеет первостепенное значение для любой организации, планирующей построить успешную модель машинного обучения в масштабе. Центральное место здесь занимает наличие всех ваших ресурсов, инструментов, библиотек и документации на единой корпоративной платформе, которая будет способствовать совместной работе, а не препятствовать ей.
Тонкая настройка предварительно обученной модели
Присоединяйтесь к сообществу Hugging Face
и получите доступ к расширенной документации
Совместная работа над моделями, наборами данных и пространствами
Более быстрые примеры с ускоренным выводом
Переключение между темами документации
для начала работы
Использование предварительно обученной модели дает значительные преимущества. Это снижает затраты на вычисления, ваш углеродный след и позволяет вам использовать самые современные модели без необходимости обучать их с нуля. 🤗 Transformers предоставляет доступ к тысячам предварительно обученных моделей для широкого круга задач. Когда вы используете предварительно обученную модель, вы обучаете ее на наборе данных, специфичном для вашей задачи. Это известно как тонкая настройка, невероятно мощная тренировочная техника. В этом руководстве вы настроите предварительно обученную модель с выбранной вами структурой глубокого обучения:
- Настройте предварительно обученную модель с помощью 🤗 Transformers Trainer.
- Тонкая настройка предварительно обученной модели в TensorFlow с помощью Keras.
- Тонкая настройка предварительно обученной модели в родном PyTorch.
Подготовьте набор данных
Перед точной настройкой предварительно обученной модели загрузите набор данных и подготовьте его для обучения. В предыдущем руководстве показано, как обрабатывать данные для обучения, а теперь у вас есть возможность проверить эти навыки!
Начните с загрузки набора данных Yelp Reviews:
>>> из наборов данных импортировать load_dataset
>>> набор данных = load_dataset("yelp_review_full")
>>> набор данных["поезд"][100]
{'метка': 0,
'text': 'Мои ожидания от McDonalds не всегда бывают высокими. Но для того, чтобы один так эффектно потерпел неудачу... это требует чего-то особенного!\\nКассир принял заказ моих друзей, а затем тут же проигнорировал меня. Мне пришлось заставить себя перед кассиром, который открыл свою кассу, обслужить человека, стоящего позади меня. Я ждал более пяти минут гигантского заказа, который включал ровно одно детское блюдо. Увидев, как двум людям, заказавшим после меня, принесли еду, я спросил, где моя. Менеджер начал кричать на кассиров за то, что они \\"обслуживали заказы\\", когда у них не было еды. Но ни один из кассиров не находился рядом с этими элементами управления, а менеджер раздавал еду клиентам и очищал доски.\\nМенеджер был груб, отдавая мне мой заказ. Она не позаботилась о том, чтобы все было у меня в чеке, и даже не хватило приличия извиниться за плохое обслуживание.\\nЯ ел в разных ресторанах McDonalds более 30 лет. Я работал более чем в одном месте. Я ожидаю плохих дней, плохого настроения и случайной ошибки. Но у меня еще не было приличного опыта в этом магазине. Это останется местом, которого я избегаю, если только кому-то из моей группы не нужно избегать болезни из-за низкого уровня сахара в крови. Возможно, мне лучше вернуться к расово предвзятому сервису Steak n Shake!»} Как вы теперь знаете, вам нужен токенизатор для обработки текста и включения стратегии заполнения и усечения для обработки любой последовательности переменной длины. Чтобы обработать набор данных за один шаг, используйте метод 🤗 Datasets map , чтобы применить функцию предварительной обработки ко всему набору данных:
>>> from transforms import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
>>> def tokenize_function (примеры):
... вернуть токенизатор (примеры ["текст"], padding="max_length", truncation=True)
>>> tokenized_datasets = dataset.map(tokenize_function, batched=True) Если хотите, вы можете создать меньший подмножество полного набора данных для точной настройки, чтобы сократить время, необходимое:
>>> small_train_dataset = tokenized_datasets["train"].
Тренироваться
На этом этапе вы должны следовать разделу, соответствующему фреймворку, который вы хотите использовать. Вы можете использовать ссылки на правой боковой панели, чтобы перейти к нужному, и если вы хотите скрыть все содержимое для данной структуры, просто используйте кнопку в правом верхнем углу блока этого фреймворка!
Питорч
Скрыть содержимое Pytorch
Тренируйтесь с PyTorch Trainer
🤗 Transformers предоставляет класс Trainer, оптимизированный для обучения 🤗 Модели Transformers, упрощающие начало обучения без написания собственного тренировочного цикла вручную. Trainer API поддерживает широкий спектр вариантов и функций обучения, таких как ведение журнала, накопление градиента и смешанная точность.
Начните с загрузки вашей модели и укажите количество ожидаемых этикеток. Из карточки набора данных Yelp Review вы знаете, что есть пять меток: 9.0005
>>> из импорта трансформаторов AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5) Вы увидите предупреждение о том, что некоторые из предварительно обученных весов не используются, а некоторые веса выбраны случайным образом инициализирован. Не волнуйтесь, это совершенно нормально! Предварительно обученный заголовок модели BERT отбрасывается и заменяется случайно инициализированным заголовком классификации. Вы настроите эту новую головку модели на свою задачу классификации последовательностей, передав ей знания предварительно обученной модели.
Гиперпараметры обучения
Затем создайте класс TrainingArguments, содержащий все гиперпараметры, которые вы можете настраивать, а также флаги для активации различных вариантов обучения. Для этого руководства вы можете начать с гиперпараметров обучения по умолчанию, но не стесняйтесь экспериментировать с ними, чтобы найти оптимальные настройки.
Укажите, куда сохранять чекпоинты из вашего обучения:
>>> from transforms import TrainingArguments >>> training_args = TrainingArguments(output_dir="test_trainer")
Оценивать
Тренажер не оценивает производительность модели автоматически во время обучения. Вам нужно будет передать Trainer функцию для вычисления показателей и отчета о них. Библиотека 🤗 Evaluate предоставляет простую функцию с точностью , которую вы можете загрузить с помощью функции Assessment.load (дополнительную информацию см. в этом кратком обзоре):
>>> import numpy as np
>>> импорт оценить
>>> metric = Assessment.load("точность") Вызов вычислить на метрика для расчета точности ваших прогнозов. Прежде чем передавать свои прогнозы в вычисление , вам необходимо преобразовать прогнозы в логиты (помните, что все модели 🤗 Transformers возвращают логиты):
>>> def calculate_metrics(eval_pred): .
Если вы хотите отслеживать показатели оценки во время тонкой настройки, укажите параметр Assessment_strategy в аргументах обучения, чтобы сообщать о метрике оценки в конце каждой эпохи:
>>> из импорта трансформаторов TrainingArguments, Trainer >>> training_args = TrainingArguments(output_dir="test_trainer", Assessment_strategy="epoch")
Тренер
Создайте объект Trainer с вашей моделью, аргументами обучения, обучающими и тестовыми наборами данных и функцией оценки:
>>> Trainer = Trainer( ... модель=модель, ... аргументы = обучающие_аргументы, ... train_dataset = small_train_dataset, ... eval_dataset=маленький_eval_dataset, ...compute_metrics=compute_metrics, ... )
Затем настройте свою модель, вызвав train():
>>> Trainer.train()
ТензорФлоу
Скрыть содержимое TensorFlow
Обучите модель TensorFlow с помощью Keras
Вы также можете обучать модели 🤗 Transformers в TensorFlow с помощью Keras API!
Загрузка данных для Keras
Если вы хотите обучить модель 🤗 Transformers с помощью Keras API, вам необходимо преобразовать набор данных в формат, который
Керас понимает. Если ваш набор данных небольшой, вы можете просто преобразовать все это в массивы NumPy и передать их в Keras.
Давайте сначала попробуем это, прежде чем делать что-то более сложное.
Сначала загрузите набор данных. Мы будем использовать набор данных CoLA из теста GLUE, так как это простая задача классификации двоичного текста, и пока просто возьмите тренировочный сплит.
из наборов данных импортировать load_dataset
набор данных = load_dataset ("клей", "кола")
dataset = dataset["train"] # Пока просто возьмем тренировочный раздел Затем загрузите токенизатор и разметьте данные как массивы NumPy. Обратите внимание, что метки уже представляют собой список 0 и 1, поэтому мы можем просто преобразовать это напрямую в массив NumPy без токенизации!
из импорта трансформаторов AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
tokenized_data = tokenizer (набор данных ["текст"], return_tensors = "np", padding = True)
labels = np.array(dataset["label"]) # Label уже представляет собой массив из 0 и 1 Наконец, загрузите, скомпилируйте и подгоните к модели:
from transforms import TFAutoModelForSequenceClassification из tensorflow.
Вам не нужно передавать аргумент потерь вашим моделям, когда вы их компилируете() ! Автоматическое обнимание моделей лица
выберите потерю, соответствующую их задаче и архитектуре модели, если этот аргумент оставлен пустым. Вы всегда можете
отмените это, указав потерю самостоятельно, если хотите!
Этот подход отлично подходит для небольших наборов данных, но для больших наборов данных вы можете столкнуться с проблемой. Почему?
Поскольку токенизированный массив и метки должны быть полностью загружены в память, а NumPy не обрабатывает
«зубчатые» массивы, поэтому каждый токенизированный образец должен быть дополнен до длины самого длинного образца во всем
набор данных. Это сделает ваш массив еще больше, и все эти жетоны заполнения также замедлят обучение!
Загрузка данных в виде tf.data.Dataset
Если вы хотите избежать замедления обучения, вы можете вместо этого загрузить свои данные как tf.data.Dataset . Хотя вы можете написать свой собственный
tf.data конвейер, если хотите, у нас есть два удобных метода для этого:
- prepare_tf_dataset(): это метод, который мы рекомендуем в большинстве случаев. Потому что это метод в вашей модели, он может проверить модель, чтобы автоматически определить, какие столбцы можно использовать в качестве входных данных модели, и откажитесь от остальных, чтобы сделать набор данных более простым и эффективным.
- to_tf_dataset: этот метод является более низкоуровневым и полезен, когда вы хотите точно контролировать, как
ваш набор данных будет создан, если точно указать, какие столбцы
label_colsвключить.
Прежде чем вы сможете использовать prepare_tf_dataset(), вам необходимо добавить выходные данные токенизатора в ваш набор данных в виде столбцов, как показано на следующий пример кода:
def tokenize_dataset(data):
# Ключи возвращенного словаря будут добавлены в набор данных в виде столбцов
вернуть токенизатор (данные ["текст"])
набор данных = набор данных. карта (tokenize_dataset) Помните, что наборы данных Hugging Face по умолчанию хранятся на диске, поэтому это не приведет к увеличению использования памяти! Однажды добавлены столбцы, вы можете выполнять потоковую передачу пакетов из набора данных и добавлять отступы к каждому пакету, что значительно уменьшает количество токенов заполнения по сравнению с заполнением всего набора данных.
>>> tf_dataset = model.prepare_tf_dataset(dataset, batch_size=16, shuffle=True, tokenizer=tokenizer)
Обратите внимание, что в приведенном выше примере кода вам нужно передать токенизатор на prepare_tf_dataset , чтобы он мог корректно дополнять пакеты по мере их загрузки.
Если все выборки в вашем наборе данных имеют одинаковую длину и заполнение не требуется, вы можете пропустить этот аргумент.
Если вам нужно сделать что-то более сложное, чем просто заполнить образцы (например, испортить токены для маскированного языка
моделирование), вы можете использовать аргумент collate_fn вместо того, чтобы передать функцию, которая будет вызываться для преобразования
список образцов в партию и примените любую предварительную обработку, которую вы хотите. Смотрите наши
примеры или
ноутбуки, чтобы увидеть этот подход в действии.
После того, как вы создали tf.data.Dataset , вы можете скомпилировать и подогнать модель, как и раньше:
model.compile(optimizer=Adam(3e-5)) model.fit(tf_dataset)
Тренируйтесь в родном PyTorch
Питорч
Скрыть содержимое Pytorch
Trainer позаботится о цикле обучения и позволяет настроить модель с помощью одной строки кода. Для пользователей, которые предпочитают писать свой собственный цикл обучения, вы также можете настроить модель 🤗 Transformers в родном PyTorch.
На этом этапе вам может потребоваться перезагрузить ноутбук или выполнить следующий код, чтобы освободить память:
del model дель pytorch_model дель тренер torch.cuda.empty_cache()
Затем вручную выполните постобработку tokenized_dataset , чтобы подготовить его к обучению.
-
Удалите столбец
text, поскольку модель не принимает необработанный текст в качестве входных данных:>>> tokenized_datasets = tokenized_datasets.
remove_columns(["текст"]) -
Переименуйте столбец
labelвlabels, поскольку модель ожидает, что аргумент будет называтьсяlabels:>>> tokenized_datasets = tokenized_datasets.rename_column("метка", "метки") -
Установите формат набора данных для возврата тензоров PyTorch вместо списков:
>>> tokenized_datasets.set_format("факел")
Затем создайте меньший набор данных, как показано ранее, чтобы ускорить тонкую настройку:
>>> small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000)) >>> small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
DataLoader
Создайте DataLoader для обучающих и тестовых наборов данных, чтобы вы могли перебирать пакеты данных:
>>> from torch.utils.data import DataLoader >>> train_dataloader = DataLoader (small_train_dataset, shuffle = True, batch_size = 8) >>> eval_dataloader = DataLoader(small_eval_dataset, batch_size=8)
Загрузите вашу модель с количеством ожидаемых меток:
>>> из импорта трансформаторов AutoModelForSequenceClassification >>> model = AutoModelForSequenceClassification.
Оптимизатор и планировщик скорости обучения
Создайте оптимизатор и планировщик скорости обучения для точной настройки модели. Используем оптимизатор AdamW от PyTorch:
>>> from torch.optim import AdamW >>> оптимизатор = AdamW(model.parameters(), lr=5e-5)
Создайте планировщик скорости обучения по умолчанию из Trainer:
>>> from transforms import get_scheduler >>> число_эпох = 3 >>> num_training_steps = num_epochs * len(train_dataloader) >>> lr_scheduler = get_scheduler( ... имя = "линейный", оптимизатор = оптимизатор, num_warmup_steps = 0, num_training_steps = num_training_steps ... )
Наконец, укажите устройство для использования графического процессора, если у вас есть к нему доступ. В противном случае обучение на CPU может занять несколько часов вместо пары минут.
>>> импортный факел
>>> устройство = torch.device("cuda") if torch.cuda. is_available() else torch.device("cpu")
>>> model.to(device) Получите бесплатный доступ к облачному графическому процессору, если у вас его нет, с размещенным ноутбуком, таким как Colaboratory или SageMaker StudioLab.
Отлично, теперь вы готовы к тренировке! 🥳
Тренировочный цикл
Чтобы отслеживать прогресс обучения, используйте библиотеку tqdm, чтобы добавить индикатор выполнения по количеству шагов обучения:
>>> из tqdm.auto импортировать tqdm
>>> progress_bar = tqdm (диапазон (num_training_steps))
>>> модель.поезд()
>>> для эпохи в диапазоне (num_epochs):
... для партии в train_dataloader:
... пакет = {k: v.to(устройство) для k, v в batch.items()}
... выходы = модель (** партия)
... потери = выходы. потери
... потеря.назад()
... оптимизатор.шаг()
... lr_scheduler.step()
... оптимизатор.zero_grad()
... progress_bar.update(1) Оценивать
Точно так же, как вы добавили функцию оценки в Trainer, вам нужно сделать то же самое, когда вы пишете свой собственный цикл обучения. Но вместо того, чтобы вычислять и сообщать метрику в конце каждой эпохи, на этот раз вы будете накапливать все пакеты с add_batch и вычислять метрику в самом конце.
>>> оценка импорта
>>> метрика = оценить.загрузить("точность")
>>> модель.eval()
>>> для партии в eval_dataloader:
... пакет = {k: v.to(устройство) для k, v в batch.items()}
... с torch.no_grad():
... выходы = модель (** партия)
... логиты = выходы.логиты
... прогнозы = torch.argmax(logits, dim=-1)
... metric.add_batch (прогнозы = прогнозы, ссылки = пакет ["метки"])
>>> metric.compute() Дополнительные ресурсы
Дополнительные примеры тонкой настройки см. по адресу:
-
🤗 Преобразователи Примеры включают скрипты для обучения общим задачам НЛП в PyTorch и TensorFlow.
-
🤗 Записные книжки Transformers содержат различные записные книжки по тонкой настройке модели для конкретных задач в PyTorch и TensorFlow.
←Предварительная обработка Распределенное обучение с помощью 🤗 Accelerate→
Обучение моделированию с помощью машинного обучения
Добро пожаловать в часть 6 нашего учебника по науке о данных. В этом руководстве мы шаг за шагом проведем вас через процесс обучения модели . Поскольку мы уже сделали сложную часть, фактическая подгонка (т. е. обучение) нашей модели будет довольно простой.
Есть несколько ключевых методов, которые мы обсудим, и они стали широко признанными передовыми методами в этой области. Опять же, это руководство предназначено для мягкого введения в науку о данных и машинное обучение, поэтому мы пока не будем вдаваться в подробности. У нас есть много других руководств для этого.
Как обучать модели машинного обучения
Наконец-то пришло время построить наши модели! Может показаться, что нам потребовалось некоторое время, чтобы добраться сюда, но на самом деле профессиональные специалисты по данным тратят большую часть своего времени на шаги, ведущие к этому шагу:
- Изучение данных.
- Очистка данных.
- Разработка новых функций.
Опять же, это потому, что более качественные данные превосходят более сложные алгоритмы .
В этом руководстве вы узнаете, как настроить весь процесс моделирования, чтобы максимизировать производительность при защита от переоснащения . Мы будем менять алгоритмы и автоматически находить лучшие параметры для каждого из них.
Разделить набор данных
Давайте начнем с важного, но иногда упускаемого из виду шага: траты ваших данных. Думайте о своих данных как о ограниченном ресурсе .
- Часть из них можно потратить на обучение модели (т.е. скормить алгоритму).
- Часть из них можно потратить на оценку (тестирование) вашей модели.
- Но вы не можете повторно использовать одни и те же данные для обоих!
Если вы оцениваете свою модель на тех же данных, которые вы использовали для ее обучения, ваша модель может быть очень переобученной, и вы даже не узнаете об этом! О модели следует судить по ее способности предсказывать новых, невидимых данных .
Поэтому у вас должны быть отдельные наборы данных для обучения и тестирования.
Тренировочные наборы используются для подгонки и настройки ваших моделей. Тестовые наборы откладываются как «невидимые» данные для оценки ваших моделей.
Всегда следует разделять данные до , делая что-нибудь еще. Это лучший способ получить надежные оценки производительности ваших моделей. После разделения данных не трогайте тестовый набор , пока не будете готовы выбрать окончательную модель!
Сравнение производительности теста и обучения позволяет нам избежать переобучения… Если модель работает очень хорошо на обучающих данных, но плохо на тестовых данных, то это переоснащение.
Что такое гиперпараметры?
До сих пор мы вскользь говорили о «тюнинговых» моделях, но теперь пришло время подойти к теме более формально. Когда мы говорим о настройке моделей, мы конкретно имеем в виду настройку гиперпараметров.
В алгоритмах машинного обучения есть два типа параметров. Ключевое отличие состоит в том, что параметры модели могут быть изучены непосредственно из обучающих данных, а гиперпараметры — нет.
Параметры модели — это изученные атрибуты, определяющие отдельные модели . Их можно узнать непосредственно из обучающих данных.
- напр. коэффициенты регрессии
- напр. местоположения разделения дерева решений
Гиперпараметры выражают «высокоуровневые» структурные настройки для алгоритмов. Они решаются до подбора модели, потому что их нельзя извлечь из данных.
- напр. сила штрафа, используемого в регуляризованной регрессии
- напр. количество деревьев для включения в случайный лес
Что такое перекрестная проверка?
Теперь пришло время представить концепцию, которая поможет нам настроить наши модели: перекрестную проверку. Перекрестная проверка — это метод получения надежная оценка производительности модели с использованием только ваших обучающих данных .
Существует несколько способов перекрестной проверки. Самый распространенный из них, 10-кратная перекрестная проверка , разбивает ваши обучающие данные на 10 равных частей (т.
Вот шаги для 10-кратной перекрестной проверки:
- Разделите данные на 10 равных частей или «складок».
- Обучите свою модель 9 складкам (например, первые 9складки).
- Оцените на 1 оставшейся «удерживаемой» складке.
- Выполните шаги (2) и (3) 10 раз, каждый раз придерживая другую складку.
- Усреднение производительности по всем 10 удерживающим фальцам.
Средняя производительность по 10 удерживающим сгибам – это ваша окончательная оценка производительности, также называемая баллом перекрестной проверки . Поскольку вы создали 10 мини-сплитов поезд/тест, эта оценка обычно довольно надежна.
Подгонка и настройка моделей
Теперь, когда мы разделили наш набор данных на наборы для обучения и тестирования и узнали о гиперпараметрах и перекрестной проверке, мы готовы подогнать и настроить наши модели. По сути, все, что нам нужно сделать, это выполнить весь цикл перекрестной проверки, описанный выше, для каждого набора значений гиперпараметров , которые мы хотели бы попробовать.
Высокоуровневый псевдокод выглядит следующим образом:
Псевдокод для настройки гиперпараметров
| Для каждого алгоритма (например, регуляризованная регрессия, случайный лес и т. д.): Для каждого набора значений гиперпараметров: Выполните перекрестную проверку с использованием обучающего набора. Рассчитать перекрестную оценку. |
В конце этого процесса у вас будет перекрестная оценка для каждого набора значений гиперпараметров… для каждого алгоритма.
Например:
Затем мы выберем лучший набор гиперпараметров в каждом алгоритме .
Псевдокод для выбора гиперпараметров
| Для каждого алгоритма: Сохраните набор значений гиперпараметров с лучшим показателем перекрестной проверки. Переобучите алгоритм на всей обучающей выборке (без перекрестной проверки). |
Это что-то вроде Голодных игр… каждый алгоритм отправляет на финальный отбор своих «представителей» (то есть модель, обученную на лучшем наборе значений гиперпараметров).
Выберите победившую модель
К этому моменту у вас будет одна «лучшая» модель для каждого алгоритма , настроенного с помощью перекрестной проверки. Самое главное, пока вы использовали только обучающие данные. Теперь пришло время оценить каждую модель и выбрать лучшую в стиле «Голодных игр».
«Я добровольно отдаю дань уважения!» Поскольку вы сохранили тестовый набор как действительно невидимый набор данных, теперь вы можете использовать его для получения надежной оценки производительности каждой модели.
Существует множество показателей эффективности , из которых вы можете выбирать. Мы не будем тратить на них слишком много времени здесь, но в целом:
- Для задач регрессии мы рекомендуем Среднеквадратическая ошибка (MSE) или Средняя абсолютная ошибка (MAE) . (Чем меньше значение, тем лучше)
- Для задач классификации мы рекомендуем Площадь под кривой ROC (AUROC) . (Чем больше значение, тем лучше)
Процесс очень прост:
- Для каждой из ваших моделей сделайте прогнозы на тестовом наборе.
- Рассчитайте показатели производительности, используя эти прогнозы и целевую переменную «наземной истины» из тестового набора.
Наконец, используйте эти вопросы, чтобы помочь вам выбрать победившую модель:
- Какая модель продемонстрировала наилучшие результаты на тестовом наборе? (производительность)
- Хорошо ли он работает по различным показателям производительности? (надежность)
- Были ли у него также (одни из) лучшие результаты перекрестной проверки из тренировочного набора? (согласованность)
- Решает ли это первоначальную бизнес-задачу? (условие победы)
На этом этап обучения модели рабочего процесса машинного обучения завершен.